Lately, I bought some random, noname spy camera from usual Chinese sources. Just after unboxing, one detail seemed a bit suspicious to me: together with the camera there comes a link to Android app, that is meant to control the camera. What is worse, the link leads to some Chinese app shop, obviously with only one language available (notice the version – 1.0.33, as it is not the only one in the wild):
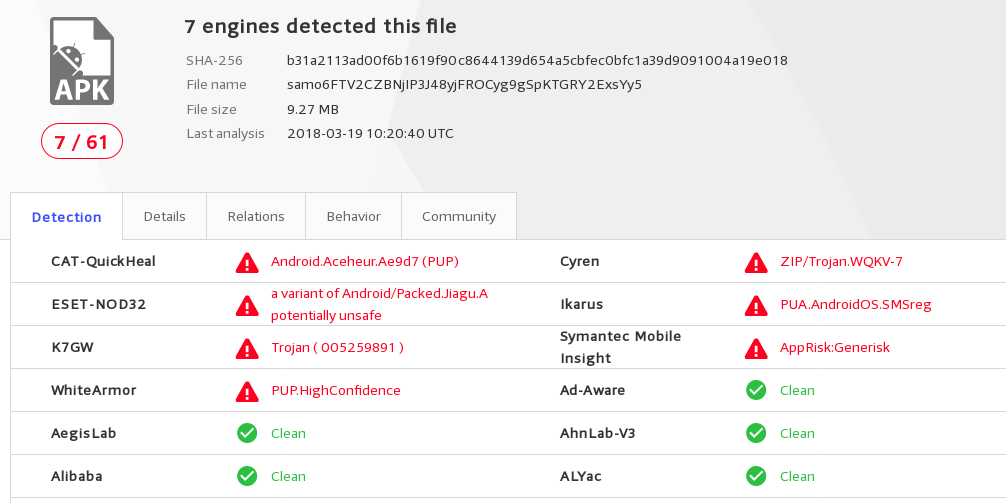
As I’ve already seen apps that i.e. calls home, despite having no need to open a single socket and then sending data like IMEI, IMSI, MAC addresses and so on, red lamp turned on and I said to myself: stop. Let’s reverse engineer the thing first!
OSINT
Before I begun my reverse engineering, I attempted to ask uncle Google (and his friends 🙂 ) to gain some knowledge. Usual virustotal gives me this:
Few weeks ago I made an attempt to reverse engineer some obscure Android APK. It was available only through some Chinese shop, obviously described in only one language there. Unfortunately, it turned out that every tool designed for reverse engineering APK files outputted source with mysterious resource IDs, as plain integers, which is not the most convenient way to read them. Therefore I started looking for any way to find some meaningful name from these ids. At the end of my development effort I found out, there is one file that usually might be used for that purpose – res/values/public.xml, as produced by apktool (if I remember correctly). However, according to its name it contains only public resources, so some of them are missing there (in my case at least some drawable type resources were missing). Therefore, I am publishing my program to do things even more reliably.
arscutils
This program requires my library created together, but which is separate project – libarsc. It is available, as usually through Github and also as a package to be downloaded from PyPI. Just type:
Recently, I bought LKV373A which is advertised as HDMI extender through Cat5e/Cat6 cable. In fact it is quite cheap HDMI to UDP converter. Unfortunately its inner workings are still more or less unknown. Moreover by default it is transmitting 720p video and does not do HDCP unpacking, which is a pity, because it is not possible to capture signal from devices like cable/satellite TV STB devices. That is why I started some preparations to reverse engineer the thing.
Fortunately a few people were interested by the topic before (especially danman, who discovered second purpose for the device). To make things easier, I am gathering everything what is already known about the device. For that purpose I created project on Github, which is to be served as device’s wiki. Meanwhile I was also able to learn, how more or less firmware container is constructed. This should allow everyone to create custom firmware images as soon as one or two unknowns will be solved.
First one is method for creation of suspected checksum at the very end of firmware image. This would allow to make modifications to filesystem. Other thing is compression algorithm used to compress the program. For now, it should be possible to dissect the firmware into few separate fragments. Below I will describe what I already know about the firmware format.
ITEPKG
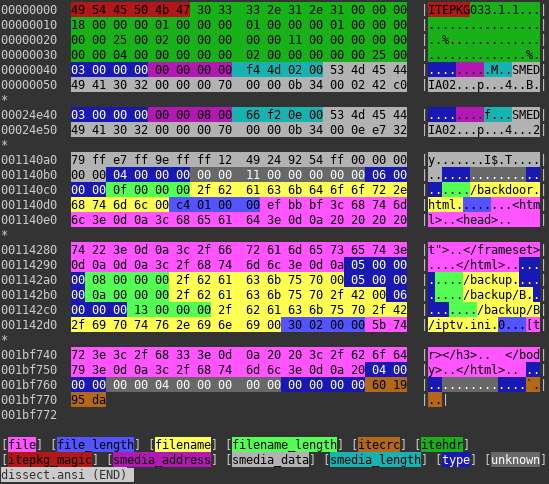
ITEPKG format (container content discarded)
Whole image starts with magic bytes ITEPKG, so this is how I call outer container of the image. It allows to store data of few different formats. Most important is denoted by 0x03 type. It stores another data container, that is almost certainly storing machine code for bootloader, and another entity of same type that stores main OS code. This type is also probably storing memory address at which content will be stored after uploading to device. Second important entity is denoted by type 0x06 and means regular file. It is then stored internally on FAT12 partition on SPI flash. There is also directory entry (0x05), that together with files creates complete partition.
SMEDIA
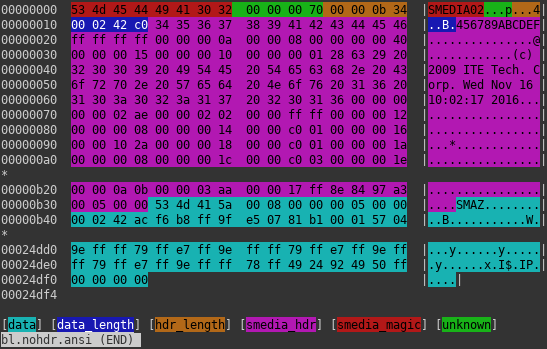
SMEDIA container (header truncated)
Another data container mentioned on previous section is identifiable by magic SMEDIA. It consists of two main parts. Their lengths are stored at the very beginning of the header. First one is some kind of header and contains unknown data. Good news is that it is uncompressed. Second one is another container. Now the bad news is that it contains compressed data chunks.
SMAZ
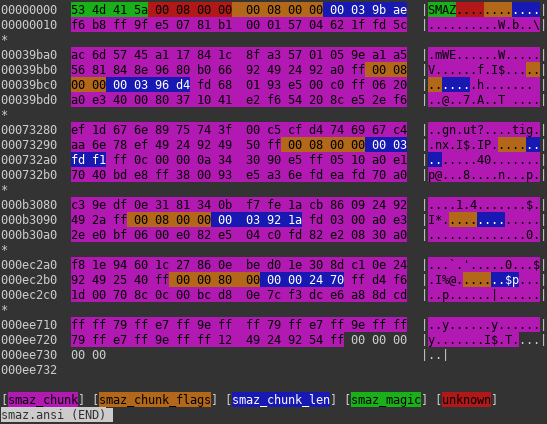
SMAZ container
This container’s function is to split data into chunks. One chunk has probably maximum length of 0x40000 bytes (uncompressed). Unfortunately after splitting, they are compressed using unknown algorithm, behaving similarly to LZSS and I have some previous experience with variant of LZSS, so if I say so it is very likely that it is true 🙂 . As for now, I reached the wall, but I hope, I’m gonna break it some time soon. Stay tuned!
NOTE: This post was imported from my previous blog – v3l0c1r4pt0r.tk. It was originally published on 10th February 2016.
As any observer of my projects spotted, most of the biggest projects I do involves binary file analysis. Currently I am working on another one that requires such analysis.
Unfortunately such analysis is not an easy task and anything that will ease this or speed it up is appreciated. Of course there are some tools that will make it a bit easier. One of them is hexdump. Even IDA Pro can make it easier a bit. Despite them I always felt that something is missing here. When creating xSDM and delz utils, I was using hexdump output with LibreOffice document to mark different structure members with different colors. It worked, but selecting 100-byte buffer line by line was just wasting precious time.
Solution
SDC file analyzed by HDCB script
So why not automate whole process? What we really need here is just hexdump output and terminal emulator with color support. And that’s why I’ve made HDCB – HexDump Coloring Book. Basically it is just extension to bash scripting language. Goal was to create simple script that will hide as much of its internals from end-user and allow user to just start it will his shell using old good ./scriptname.ext and that’s it. HDCB is masked as if it was standalone scripting language. It uses shebang, known from bash or python scripts to let user shell know what interpreter to use (#!/usr/bin/env hdcb). Those who are python programmers should recognize usage of env binary.
In fact it is just simple extension to bash language, so users are still able to utilize any features available in bash. Main extensions are two commands: one (define) for defining variables and the other (use) for defining field or array of that defined type. Such scripts should be started with just one argument – file that is meant to be hexdumped and analyzed.
Internals
Bash scripts are just some kind of a cover of real program. Main core of the program is colour utility. It gets unlimited number of parameters grouped in groups of four. They are in order: offset of byte being colored, length of the field, background and foreground colors. As standard input, hexdump output (in fact only hexdump -C or hexdump -Cv are supported) is provided. Program colors the hexdump with rules provided as arguments. This architecture allows clever hacker to build that cover mentioned in virtually any programming language.
Downloads, documentation and more
As usual, program is available on my Github profile. Sources are provided on GPLv3 license so you are free to contribute to the project and you are strongly encouraged to do so or make proposals of a new functions. Program is meant to be expanded according to my future needs, but I will try to implement any good idea. Whole documentation, installation instructions and the like are also available on Github.
NOTE: This post was imported from my previous blog – v3l0c1r4pt0r.tk. It was originally published on 6th November 2015.
Last year, I published a program for Microsoft Dreamspark’s SDC file decryption. Soon after that I wrote article about SDC file format and its analysis. Now it’s time to complete the description with newest data.
This article wouldn’t be written if not the contribution of GitHub’s user @halorhhr who spotted multi-file SDC container and let me know on project’s page. Thanks!
When writing that post year ago, I had no idea what multi-file container really looks like. Any suspicions could not then be confirmed, because it seemed that these files simply where not used in the wild. A days ago situation changed. I got a working sample of multi-file container so I was able to start its analysis.
Real container format
SDC files with different signatures
After quick analysis, I knew that I was wrong with my suspicions. Filename length and encrypted filename strings are not part of a file description. In fact they are placed after them and filename is concatenated string of all filenames (including trailing null-byte). So to sum up filename of n-th element starts at file[n].filename_offset and ends just like any other c-style string.
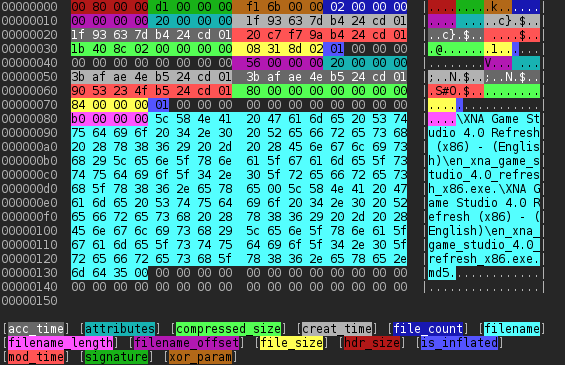
Whole header structure is like on the sample header on the right. Note that all headers beside 0xb3 one has been already decrypted for readability. In real header the only unencrypted field is header size at the very beginning of the file. 0xb3 sample has unencrypted header and header size is not present in a file. However file name is encrypted in some way, I haven’t figured out as of now. Encryption method is blowfish-compat (the difference between this and blowfish is ciphertext endiannes). Filenames are encrypted once again.
After header, all other data is XORed using key from EDV string and then deflated, so before reading them, you have to inflate and XOR again. Format of data in 0xb3 version is still unknown, however analysis of compressed and file size hints that it may be stored the same way. It is important to note that depending on file signature different configuration of deflater may be needed. It is now known that files older than 0xd1 header, which appears to be newest (because only this one supports files greater than 4 GiB) need to have deflater initialized with
This errata does not contain all information needed to support all variations of SDC files. Beside unknowns I mentioned above, there is another variation that uses 0xc4 signature and which I had no sample of. The only trace of its existence is condition in SDM code. Because of that I cannot write support for that type of file. There is also possibility of multi-file containers having 0xb5 or 0xb3 signatures existence. That type of files seems to appear only lately, but it is probable that it existed in the past. Because of having no samples of them I cannot verify that xSDM properly handles them.
So if you have sample of any of variations mentioned here, just send them to me at my email address: v3l0c1r4pt0r at gmail dot com or if you suppose it may be illegal in your country, just send me SDX link or any other hint for me how can I find them.
Other way?
Few days ago, after I started writing this post Github user @adiantek let me know in issues that there is a method to obey SDM in Dreamspark download process. To download plain, unencrypted file you just have to replace ‘dfc=1‘ to ‘sdm=0‘ in a link Dreamspark provided in SDX file. If it true that it works in every file Dreamspark provides, my xSDM project would be obsolete now. However, because Microsoft’s intentions when creating this backdoor (it seems to be created just for debugging) are unknown, I will continue to support the project and fix any future bugs I will be aware of. But now it seems that this project will start to be just proof of concept for curious hackers and will start to slowly die.
Nevertheless, if you have something that might help me or anyone who may be interested in SDC format in future, just let me know somehow, so it will be available somewhere on the internet.
NOTE: This post was imported from my previous blog – v3l0c1r4pt0r.tk. It was originally published on 1st August 2015.
About a year ago I interested in mysterious 2D code placed in my car’s registration certificate. After quick research on Google it turned out to be even more mysterious because nobody knew how to decode it. There was even no official document like act or regulation that describes the code somehow. People knew that the code is Aztec code and that’s it. Some companies shared web and Android apps to decode this. And all of them was sending base64 to some server and receive decoded data.
Of course for me it wasn’t rewarding so I started my research on it. After initially scanning the code I’ve seen long string that I immediately recognized as base64. The real fun started after that, because stream I’ve got after that was so strange that at first I had no idea what to do. Upon closer examination it was clear that this data is not damaged but encoded in somewhat strange way. Few days later I was almost sure that this is not encoding but rather compression, because some unique parts of stream was easily readable by human. About a month of learning about compression, looking for even most exotic decompression tools and I was left with almost nothing. I had only weak guess on how decompression parameters could be encoded. I gave up…
About a year later I tried one more time. This time I was a bit more lucky. I found a program that decodes the code. Again. But this time was different. I shut down my network connection to make sure. And it worked! So now a bit of reverse engineering and it’s done. I will skip any details because I do not want to piss off the company which created this, even though I was right and I HAD right to do this.
As usual the source code is available on my Github profile. There is also a bit more information about whole scanning/decoding process. If you like to know more technical details about the algorithm or how to decode the data, everything can be found in README file in the repo.
NOTE: This post was imported from my previous blog – v3l0c1r4pt0r.tk. It was originally published on 22nd June 2014.
As promised in my previous post I’m publishing description of Microsoft’s SDC file format. At the beginning I’d like to explain what SDC file is. SDC is the abbreviation of Secure Download Cabinet/Secure Digital Container. It is used by Microsoft in its Dreamspark program (formerly MSDNAA). Theoretically it is secure container that can be sent using Internet without additional encryption and it should prevent its content from being read by any third party. But that’s theory, let’s look at how it works in practice.
Overview
Firstly let’s look at the packing process. Let’s say we are in Microsoft and we want to “secure” some data. We got some file (or possibly few files) ie. Windows ISO. Next we generate some random number and write it down somewhere. Now we use least significant byte of that number to do XOR on EVERY single byte of that file. Now it may be considered secure 🙂 But some day Microsoft realized it isn’t enough. So what did they do? They used deflate (it is compression method used ie. in zip, gzip). Actually there are two versions of the deflate: one with all headers necessary to realize method of compression by using a tool like binwalk and the other that haven’t any header. Now it is time to combine all the files we have in one. Of course we still need to know some information about them (ie. their size before/after compression, file name). After concatenation we need to count CRC of all the data we have as of now. And finally we need to build a file header. At first we need to write header size. Then starts actual header. It is important because here starts region that will be encrypted. Here is some info about the header itself and then about each file. It is possibly padded with random data (don’t know for sure). Now we need two random 32-byte keys consisting of printable characters. We use first to encrypt filenames and the second to encrypt whole header (beside its size). Finally we concatenate header with the rest and here we have SDC file.
Header format
Sample header
So, we have basic overview on the format, now let’s look at the details. You think it isn’t secure, huh? It would be worse. On the right you can see example header after decryption. First four bytes determine size of the header counting from the next byte. After that we have area encrypted using Blowfish (sometimes referred blowfish-compat) with ECB mode (Electronic CodeBook) using the key stored in edv variable of webpage linked from SDX file. In that area we have 3 dwords describing the header itself. First is header signature. It can be one of the following values: 0xb4, 0xb5, 0xc4, 0xd1. All I know now is that the one with sig = 0xd1 can store files larger than 4 GiB. The next value is interesting one. It looks like it is used to “encrypt” file name in memory so that the static analysis would result in “not found”. As in other cases it is “very advanced encryption”, the same situation as with the whole file: get all the buffer, iterate through it and XOR with the value’s LSB. I have to admit that this one is even does the job. Now we have something called header size. Actually it is probably number of files packed in the container. While reversing I concluded that SDM iterates from 0 to that number, and while this it is reading 0x38 bytes from file. Next it is probably reading fileNameLength and fileName, so whole header must be in format:
and so on until we reach headerSize. Then we have a lot of values not necessary to unpack the file. First of them is offset of file name. While its value is usually 0 (at least in newer headers with blowfish encryption) it is still probably possible to encounter a file with this value greater than zero. If that happened the first thing to do is probably decrypt filename and then move pointer this amount of bytes right. Next value describes file attributes. In fact I didn’t bother about what bit means what attribute, but I suppose it is the same map as in FAT (see my libfatdino library). The next three values are timestamps (creation, access and modification). They all are in Windows 64-bit format called “file time” used for instance by .NET Framework’s DateTime class (DateTime.FromFileTime method; they are number of 100-nanosecond ticks that elapsed since epoch at 1st January 1601 midnight and I suppose that this value is unsigned). That format is very interesting in comparison with another approach of saving date on 64-bit value used on Linux. UNIX timestamp traditionally uses 1st January of 1970 as its epoch and there is usually signed value in use. It isn’t as precise as Windows (counts only seconds) but its end is about 300 billion (10^9) years in future and since it is signed, in past too. Comparing to that Windows’ date will wrap about year 60000 A.C. and cannot store any date before 1601. I know that is still unreachable (like 4 billion computers in 80’s 🙂 but good to know:) After that we have size of the compressed file (be beware of the difference between 64-bit variant and 32-bit one). When we have container with only one file the equation
compressedSize + headerSize + 4 == sdcSize
should always be true. The next one is uncompressed size of the file which can be used to check if the file has been downloaded entirely. After that there is boolean that indicates if file is inflated (compressed), another one-byte value that is probably reserved for future use, one-word padding, which is also interesting because it looks like it contains random numbers (really?). And after that more padding (this time empty) after which we have size of the file name. It may be a bit tricky because the size we have here is the size AFTER decryption and blowfish demands its output to have length divisible by 8. So to decrypt it we need to count next divisor of 8. File name is encrypted using the same method as the header itself and the second key from edv.
Decryption key
Now something more about the keystring (edv). Its format is:
<crc>^^<fileNameKey><headerKey><xorKey>
where:
<crc> is a checksum of whole data area of a file (everything beside header size and header)
<fileNameKey> is the key used to encrypt file names
<headerKey> is the key used to encrypt whole header
<xorKey> is the key used to “encrypt” the files
Security of the whole program
People who are familiar with security should already know how insecure is the SDM. For others I have short description.
At first the files itself AREN’T ENCRYPTED in any way. They are only XORed using one byte long key. XOR itself is very weak protection, even with extremely long key. It is due to the fact that many file formats have some of their bytes predictable (this concerns EXEs, ISOs and ZIPs and these are the formats most frequent on Dreamspark). That predictable bytes are usually the beginnings (headers) which usually have so called magic bytes to easily identify file format. So when we know what byte we expect we could try to XOR that byte with actual byte and it is very probable that we get the “encryption” key.
Deflate which is used to hide this patterns from the end user is just compression method. We don’t need anything special to decompress this data.
ECB which is used as blowfish encryption mode is the most insecure mode of block ciphers. It can cause some parts of data to be revealed without actual decryption (see: Wikipedia).
All the data SDM downloads/sends from/to Microsoft’s servers are UNENCRYPTED. Everything: request from the user, SDC itself and decryption keys are all plaintext so with knowledge how SDC looks we can decrypt the file even when it is not intended for us, but we are only in the middle of its road. Furthermore malicious node is able to modify the file on the fly and i.e. put a backdoor into the file, for instance Windows image.
Conclusion
For all the above reasons Secure Download Manager cannot be called a software for securely downloading the files from Microsoft’s servers. All the users using this are the same way INSECURE as users downloading i.e. their copy of Windows from warez sites. Both are susceptible to MITM attacks.
So we still don’t know the answer: why Microsoft is using dedicated software to share their software. The only answer I have is that it is just for making user’s not using Microsoft’s operating system life difficult. In place of decision-making people like the ones in European Commission I would think if this policy is not intended to be only to keep Microsoft’s monopoly for operating system.
Update 20.07.2014
Description updated thanks to GMMan and his great work on reverse engineering the whole program. He also reminded me about older variants of SDC files. I have currently sample(s) of files with 0xb3, 0xb5 and 0xd1 signatures. I know at the moment that there are also signatures 0xa9, 0xb2, 0xb4, 0xc4 and it is possible that they still are reachable through Dreamspark. It is also likely that Microsoft (or Kivuto on Microsoft’s order) will create new format so if you have a sample of file with different header, please let me know in comments!
NOTE: This post was imported from my previous blog – v3l0c1r4pt0r.tk. It was originally published on 17th September 2013.
Today it’s finally time to introduce my first Linux project. Its main function is to provide all functions needed to handle block device formatted using FAT32 volume. For now it is early alpha providing only functions for reading. It also contain simple C++ demo that was used initially for testing. Main program repository is placed on github, so I hope all progress will be immediately uploaded and available for everyone. Whole library has been written in C with building scripts in make so it is possible to port it to every environment including BIOS which is as mentioned below one of its targets. Compilation should also be possible on environments other than Linux i.e. Windows. Important: library’s dependencies are glibc (Linux default so it shouldn’t be problem) and PCRE (found on most of the distributions) and there is no configure script as of now to check their presence so if you haven’t them you will get compilation error!
Starting to write this library I had 2 main goals. First one was to write read/write functions for use under Linux environment. This one will be achieved by completing this library. The second is to rewrite part of this lib responsible for reading to use it in pure BIOS environment. This goal will be the most important step to complete my another project that I won’t introduce here, because of really small amount of work done for now.
But you may ask: why FAT32, filesystem that really is the most ancient fs that is already in use? Answer for this question is relatively easy. The first fact that is in favor of FAT is its simplicity comparing to any modern filesystem that has features like permissions or access control lists. The other one is still considerable prevalence especially on every embedded application as cameras, phones (smart too), USB sticks.
Most of the code written here was based on Microsoft’s whitepaper entitled Microsoft Extensible Firmware Initiative FAT32 File System Specification. Few details that wasn’t included in that document is based on other people’s code found on Google so I couldn’t mention the exact names. The most interesting details that Microsoft’s whitepaper doesn’t contain is:
creation date and time values in directory entry structure
way that drivers (linux driver too) determine if file or directory that doesn’t contain Long File Name should be lowercase or uppercase
last access value encoding; that one is as of now still unsupported, I’ll try to add it after whole project is done
All functions that is already present in the lib has I think sufficiently detailed description on its header file. Their implementation is also present on other functions and on the demo app so I hope that it will not be problem to anyone to use it properly even though some caption in the demo are in Polish. The reason for that Polish strings is that demo was initially not designed to be public. To use that library some knowledge about FAT filesystem is required, because every function doesn’t contain all code needed to perform actions listed below, i.e. function that reads directory content has no code to list that directory and cannot follow cluster chain so that actions must be implemented by programmer that wants to use the lib. Of course following cluster chain is implemented in another function so there is no need to write it from scratch.
Functionalities implemented
reading a file
reading directory (with LFN support)
getting file/dir location based on its path in the filesystem
getting file’s properties
Functionalities to be implemented
writing to file
moving files
creating dirs
modifying directory entries
writing bootloader code to BPB/BS
Functions which operation isn’t visible to end user aren’t listed above so there is still lot of work to do.