I am working on a project, part of which is Android application. As using Android Studio is frustrating experience and I already failed starting some projects due to its “usefulness”, this time I decided to work the problem around as much as I can, since the project is quite important to me and amount of development to be done is rather significant. Usually I would use some low level language for that as it guarantees best performance, or Python for its ease of use. But I already have experience in building complex stuff in C/C++ and tried webapps in Python/Django, so I know it would be too much for a hobby project. At the same time I remember PHP as very nice tool for a guy who have little experience. So after preparing successful PoC for PHP side, I decided to bundle whole PHP inside of Android application. This allows to deliver environment with similar concepts as notorious Electron, but way less resource hungry. Let me present you PHP for Android development. Just to be clear I show here only binary side, no Android project configuration here, but if I manage to prepare a demo app for that, I will make it as part 2 of this post. Continue reading “PHP build for use bundled in Android applications”
Running graphical apps inside Docker containers
It happens from time to time that I want to use some application that I do not consider trustworthy. If the app is using only a console as its interface this is easy – create new disposable Docker container and that’s it. However for apps using Xorg this is not so easy. In such cases the quickest solution is to have either dedicated virtual machine, or separate PC exactly for this use case. However none of these 2 solutions is easy to use, nor is fast enough, especially for resource-hungry applications. To have smoothest experience, Docker still sounds like the best solution. Exactly for this purpose I created a template that should allow running any application closed in docker jail and even with possibility to cut it from internet access. Continue reading “Running graphical apps inside Docker containers”
Plugin architecture demo for Python projects
I started work on this concept many months ago. However I never had enough free time to get this to complete stage. Today finally I prepared the demo will all crucial features embedded. So, first, let me explain the concept. Generally the idea is to have a command that will be easily extensible with new features. The best way to achieve that is by having a kind of plugin architecture, where there is main program – in this case just an interface in fact as it does not provide any useful features on its own. And there are a lot of plugins that somehow registers to main program.
Crucial thing here is to have it done automatically, so all the user has to do is to install the plugin. Another important feature is to provide bash completion for this program, so that plugin developer can focus on interface itself, not the way of integrating it with bash and still get quite good completion. Of course in more complicated cases developer still has to do some development, but let’s ignore that here as this is not so important.
To achieve all the above I created two demo projects. One is called menu and it implements interface for plugins, do all the necessary jobs, so that plugins can live like almost independent applications, only called by menu. The other is demo plugin that uses all this magic to appear as command in menu just after its installation.
So from user perspective there are two main steps:
- Install menu and all plugins he needs with pip
- Enable bash completion as is usually done with argcomplete
Continue reading “Plugin architecture demo for Python projects”
Authorizing adb connections from Android command line (and making other service calls from cli)
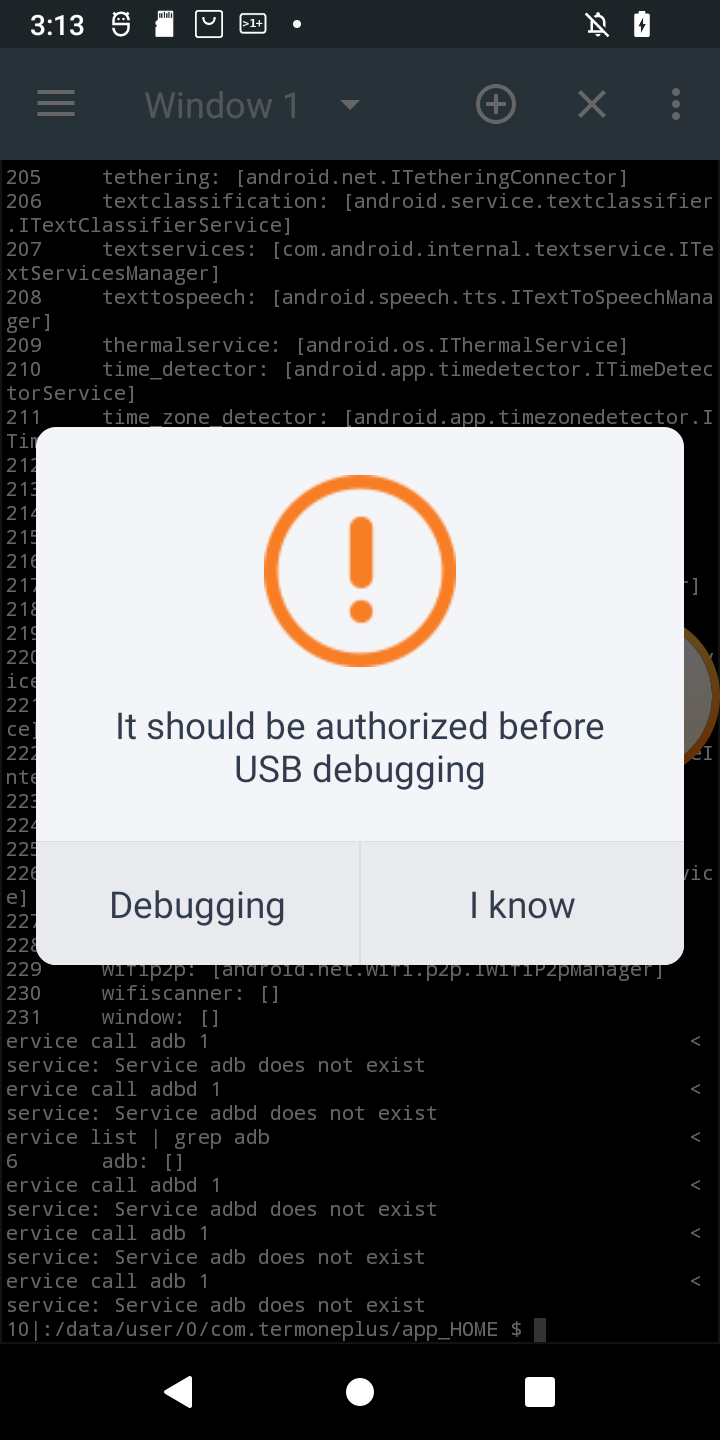
I just received POS tablet, precisely Sunmi V2s. I bought it for fraction of its prize due to alleged vendor lock. Due to that I was prepared for long fight for its freedom 😀 When starting the play it turned out that it has 14-day trial period, inside which it is possible to do almost anything in the system, just like with the ordinary Android device. Obviously one of the first things to do (especially due to this trial counting down from 14 days), was to enable adb. Developer options was enabled the usual way, but then after enabling adb and trying to connect from PC, instead of well known confirmation window with computer fingerprint, such a thing popped up on the screen:
Of course, as is usual for Chinese vendors, translation is a literal translation of Chinese glyphs into English words, so I had to click both buttons to see the difference 🙂 Anyway when Debugging is clicked, login page appears for Sunmi partner. While registration is open, the name suggest, it might not be successful for me. So I need another way. And it seems another way exists. In my case rooting the device was required at first, but for now I will ignore that part. What I want to show is how in general start digging in service calls from command line (I think I have another interesting use case on other device 🙂 ). So, without boring you all, even more, let’s get started. Continue reading “Authorizing adb connections from Android command line (and making other service calls from cli)”
How to recover torrent from rtorrent meta files
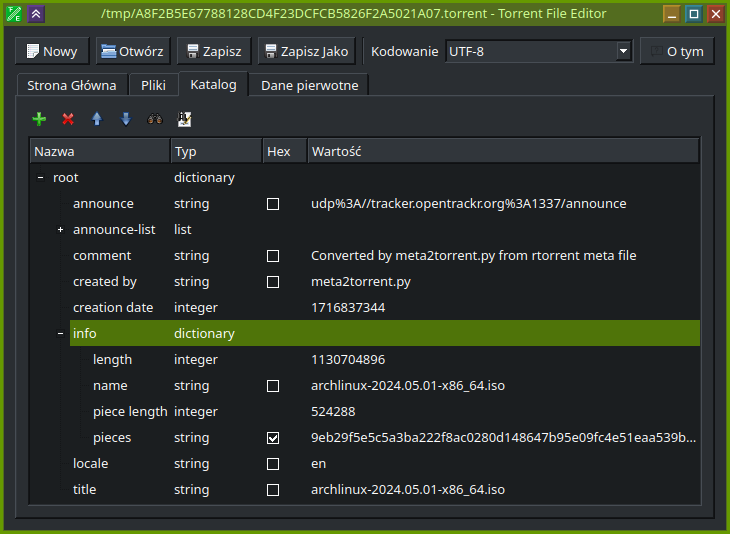
rtorrent is very nice tool to download torrents quickly and on headless systems. However, while making such a quick use, I was caught by its weird design decision that it comes unconfigured and while not configured explicitly it does not store its session in any way, even as torrent files of jobs that were started. I can imagine that in many cases it is not a problem as still usually torrent files are easily available and if not using magnet to obtain one is not a problem. Unfortunately I ran into such a weird situation where I was not able to start a job again with just a magnet link and obviously was not able to download whole torrent at one run. Also saving session in rtorrent was not working. So the only chance for me to recover download job was to use meta file that rtorrent leaves behind for reason unknown. There is even Github issue discussing those files and requesting ability to use them to recover the job. But unfortunately it is still open. So the only way for me was to do it myself. Continue reading “How to recover torrent from rtorrent meta files”
Connecting WMS services to apps able to handle only OpenStreetMap format like OsmAnd Android app
So thing is that there is a lot of interesting map data provided by state institutions (at least here in Europe), but at the same time viewer that at least Polish Geoportal provides does not provide experience good enough for everyone (that is my personal opinion) and at the same time there exist cool Android app that is able to integrate many different map providers and for some reason include neither WMS, nor WMTS support. And these two are core of services like mentioned Geoportal and seems like a standard for GIS purposes. As this seemed to me like a nice, little and easy side project, I took an opportunity. What I did is basically a wrapper that takes format used by OSM (called Slippy Map) and generates WMS-compatible request under the hood. But as you, the user, are here, you probably are not interested that much in technical details, but rather seek a solution to the problem that I had. So, here it is.
Continue reading “Connecting WMS services to apps able to handle only OpenStreetMap format like OsmAnd Android app”Pinout of laser driver for CPRI SFP+ module – GN1157

On one of the usual sources of weird electronics I came across quiet unusual SFP+ module and could not resist buying it to see how it works. For now I was unable to make it work, but at least I made few photos of its internals. It turned out its main part is obscure chip made by Semtech and described as GN1157, which serves as laser diode driver. Obviously obtaining datasheet is impossible even in China. However, thanks to being able to see the board, I was able to reverse engineer some part of its pinout. Continue reading “Pinout of laser driver for CPRI SFP+ module – GN1157”
Sniffing USB traffic with DSLogic logic analyzer into pcap file
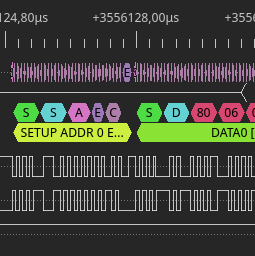
Lately I came back to reverse engineering project that I started few years ago. Direct reason for such a long break was being stuck at attempts in using usbmon to capture USB traffic. The traffic that I wanted to sniff was between router and modem that connects to it via USB. As is usual with this kind of devices there is no SDK available and compiling custom kernel module for such system, while has huge educational value, is most likely going to end up with failure. So definitely I needed another way around this problem. Fortunately I have DSLogic logic analyzer, that could easily record such a slow protocol as USB. Then a bit of exporting and you get pcap file for wireshark. This might sound like a simple task, but I am going to show that it is not necessarily is. Continue reading “Sniffing USB traffic with DSLogic logic analyzer into pcap file”
New ccfactory on its way, binutils are already here

From the beginning of current year I am learning Docker. First result of this interest on my Github was publishing ccfactory tool, which was supposed to provide easy way to produce compiler toolchains. Almost like they were mass-produced in a factory, thus the name. However, since then I learned a lot and gained some experience. At the moment it is obvious to me, what I did then is not the best design. And because the project is still very fresh, I decided to start once again, from scratch, to create way better design that will be easy to develop and maintain.
Today is time to publish first step to this new design – binutils. I would not do that, but Docker Hub allows to have only one private repo, so the way that I do it disallows me to have it private anyway. So better idea is to describe it somehow to avoid confusion. As I wrote, this first step is binutils and this is simple container that contains binutils and nothing else. My goal is to finally make toolchain base on gcc version 3.3, which might sound weird, but this is what I needed in the past and is best way to prove what this new approach can achieve. With previous one, that I will call legacy from now on, I failed in that and before failing I did even more complicated Dockerfile, than originally planned. So, when finished this one will be proof of good design, I hope. Continue reading “New ccfactory on its way, binutils are already here”
Unboxing, startup and first impression of Nezha board marketed as first affordable RISCV SBC

Some of you may have already heard about new RISCV board that popped up in China recently. It is called Nezha and is the first available SBC having new Allwinner D1 SoC with RISCV core and capable of running Linux. Authors are marketing it as first affordable RISCV Linux SBC and there is a lot of truth in these claims. Maybe this board cannot compete in any way with boards based on ARM Cortex A cores. On the other hand all previous RISCV offerings were in different galaxy in terms of price tag. $999 for Hifive Unleashed during its Crowdsupply campaign vs. $99 for Nezha on Indiegogo. They even claimed to go down as low as to $12, but as they say global supply chain problems made it impossible for now. We have to wait for all this pandemic troubles to end to check, if these claims could be verified by facts. Continue reading “Unboxing, startup and first impression of Nezha board marketed as first affordable RISCV SBC”