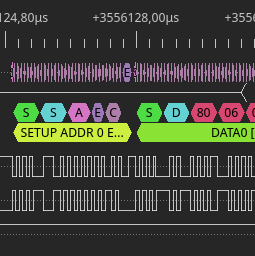
Lately I came back to reverse engineering project that I started few years ago. Direct reason for such a long break was being stuck at attempts in using usbmon to capture USB traffic. The traffic that I wanted to sniff was between router and modem that connects to it via USB. As is usual with this kind of devices there is no SDK available and compiling custom kernel module for such system, while has huge educational value, is most likely going to end up with failure. So definitely I needed another way around this problem. Fortunately I have DSLogic logic analyzer, that could easily record such a slow protocol as USB. Then a bit of exporting and you get pcap file for wireshark. This might sound like a simple task, but I am going to show that it is not necessarily is. Continue reading “Sniffing USB traffic with DSLogic logic analyzer into pcap file”





