This article is part of series about reverse-engineering LKV373A HDMI extender. Other parts are available at:
- Part 1: Firmware image format
- Part 2: Identifying processor architecture
- Part 3: Reverse engineering instruction set architecture
- Part 4: Crafting ELF
- Part 5: Porting objdump
- Part 6: State of the reverse engineering
- Part 7: radare2 plugin for easier reverse engineering of OpenRISC 1000 (or1k)
As I wrote in previous part, my choice is in fact reverse engineering instruction set. The goal of this post is not to reverse-engineer whole instruction set, because even in RISC architectures some of the instructions might be quite rarely used.
Before starting the actual reverse engineering, place where such analysis would be easiest should be identified. Then it might be possible to use often repeating patterns to guess instructions that the pattern consists of. The result of this tutorial will be description of opcodes related to jumping and few other often used opcodes, mostly related to memory operations.
Identifying target
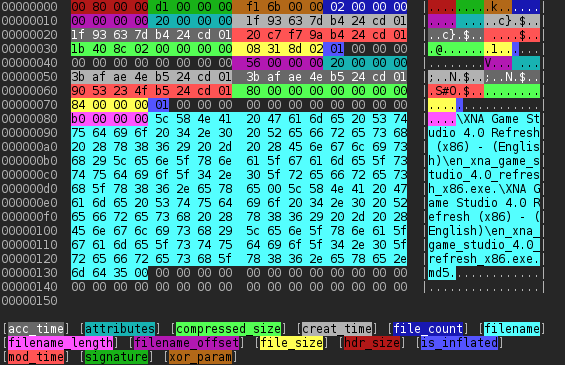
As written above, first step is to find good target. As was shown in previous article, it is possible to find references to constants mixed into code.
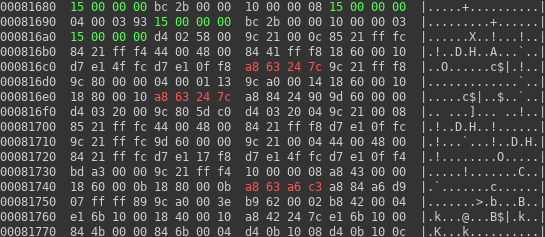
In the picture on the right one especially interesting information can be seen – it seems that as an operating system FreeRTOS was used. FreeRTOS is open source project, so its source code can be downloaded.
This information could be later possibly used to link compiled code with FreeRTOS source code. Let’s look into source code to find some useful location. As we already know the encoding of opcode for an operation on strings, finding some string in code might work. I was able to identify one such place in tasks.c file. It is shown on snippet below:
4110 if( ulStatsAsPercentage > 0UL ) 4111 { 4112 #ifdef portLU_PRINTF_SPECIFIER_REQUIRED 4113 { 4114 sprintf( pcWriteBuffer, "\t%lu\t\t%lu%%\r\n", pxTaskStatusArray[ x ].ulRunTimeCounter, ulStatsAsPercentage ); 4115 } 4116 #else 4117 { 4118 /* sizeof( int ) == sizeof( long ) so a smaller 4119 printf() library can be used. */ 4120 sprintf( pcWriteBuffer, "\t%u\t\t%u%%\r\n", ( unsigned int ) pxTaskStatusArray[ x ].ulRunTimeCounter, ( unsigned int ) ulStatsAsPercentage ); 4121 } 4122 #endif 4123 } 4124 else 4125 { 4126 /* If the percentage is zero here then the task has 4127 consumed less than 1% of the total run time. */ 4128 #ifdef portLU_PRINTF_SPECIFIER_REQUIRED 4129 { 4130 sprintf( pcWriteBuffer, "\t%lu\t\t<1%%\r\n", pxTaskStatusArray[ x ].ulRunTimeCounter ); 4131 } 4132 #else 4133 { 4134 /* sizeof( int ) == sizeof( long ) so a smaller 4135 printf() library can be used. */ 4136 sprintf( pcWriteBuffer, "\t%u\t\t<1%%\r\n", ( unsigned int ) pxTaskStatusArray[ x ].ulRunTimeCounter ); 4137 } 4138 #endif 4139 } 4140 4141 pcWriteBuffer += strlen( pcWriteBuffer );
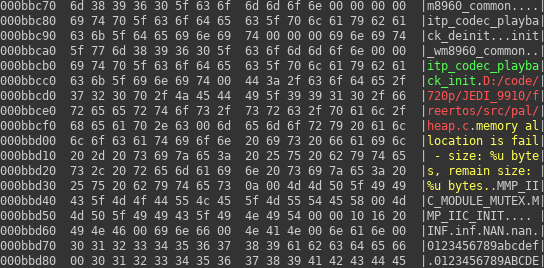
If we look at code before the snippet, we can see that the function is surrounded with ifdefs and is meant to be turned on only for demo purposes. Also searching for complete formatting string from sprintf function above fails on LKV373A firmware. Fortunately it is present in code and happens to have some modifications. One of them is the formatting string we were searching for. I was able to identify them starting at offset 0xbab2f. You can see it on hexdump. What is a bit surprising is that there are four such strings, while we expected only two in whole code. But "IDLE" string after them is confirming that it must be tasks.c module.
Now we can use method shown on previous tutorial about processor identification to find references to these strings. Finally I found usages of offsets 0xbab5c and 0xbab73 (marked in green and blue) near offset 0x91fd4.
At this moment, we have machine code and source code that is very likely to be compiled one to one into this machine code. We can also see here very useful side-effect of open source popularity: we have a system that has quite unusual function and is using open source software. So we can conclude that we can be almost sure that any random part of code also has open source software in itself.
Code patterns
As we already have quite reliable anchor for our analysis, we could try identifying more opcodes. But, to make things easier, I want to go the pattern matching way. Whichever architecture you analyze, you see some patterns that are same or almost the same on any architecture. This is especially true on RISC architectures, as they have very limited set of functions, so compiler have to join two or more instructions to get desired high level functionality. It this section, I will describe some of such patterns, I was able to identify and decode in LKV373A firmware. They are:
- Function call
- Function prologue and epilogue
- Read-only memory access
- Compare and jump
- Variadic functions
Following is short description of the above patterns.
Function call
This is main element of ABI (Application Binary Interface) from the point of view of a programmer. Therefore it should also be well-known, even to people not involved in assembly programming or reverse-engineering. It is all about the method of passing arguments, before a call to a function.
Let’s see how such a call looks on MIPS architecture:
lw gp,24(sp) nop lw s0,-32736(gp) nop addiu s0,s0,6872 lhu s0,0(s0) addiu a0,sp,34 # a0 = sp + 34 move a1,zero # a1 = 0 li a2,16 # a2 = 16 move s7,v0 sh s0,32(sp) lw t9,(get_sr_name_ptr - 0x1000BE50)(gp) nop jalr t9
As we can see in case of MIPS, arguments are passed in registers named a0, a1, a2 and so on. Then address of function to call is loaded to t9 and jalr (jump and link register) is performed. Usually, in case of ABI, where arguments are passed in registers, when number of arguments is greater than number of such registers, they are passed through memory (i.e. stack).
Function prologue and epilogue
When performing a call to different function, state of the processor have to be preserved, so after the call it is again the same as before (with exception of few registers, used e.g. for return value passing). This operation may be done by caller or callee. Let’s look again at MIPS code to see how it works there:
sw ra,5328(sp) sw s8,5324(sp) sw s7,5316(sp) sw s6,5312(sp) sw s1,5292(sp) sw s0,5288(sp) sw gp,5320(sp) sw s4,5304(sp) sw s3,5300(sp) sw s2,5296(sp)
I think there is nothing special to comment here. The opposite happens on function epilogue and additionally, immediately after that return instruction should appear.
Read-only memory access
This one is already partially analyzed on previous part of this series. It is usually appearing where some strings need to be used in code. Strings written in code as literals are stored in part of the memory where they shouldn’t be modified. Then theirs addresses are computed using some base register, or directly if code is not relocatable. This is how it works on MIPS:
lw t9,-30404(gp)
But, as we can see on previous post, we have something missing on our mysterious architecture. There, address was computed as $3=$3+0xbadadd. So, we should expect that register used should be set to something before that.
Compare and jump
This is after calling conventions, another extremely popular scheme. It usually consists of two opcodes. At first two numbers are compared, and some flags in processor are set. Then based on the state of one of the flags, jump is performed, or processing is continued if flag has value different than we expect. This time, let’s see how it works on x86 platform, as MIPS uses a bit different philosophy:
cmp [ebp+arg_4], eax jnz loc_404CEB
On x86 cmp instruction causes the subtraction of two parameters, without actually storing the result, but only updating the FLAGS register, so it is known if the value is zero, or the overflow happened, and so on. Then based on flag value (in this case if zero flag is not set), jump occurs, or not.
Variadic function
Variadic function is function that can get variable number of parameters. The most popular example of such function is printf. It accepts format string and parameters, which number depend on format string. On system, where parameters are passed through registers, I expect it to get format through register and rest of parameters through stack or dedicated structure, so generally memory. Once we know how constants are accessed, it should be quite easy to identify, as it most likely will get format string as one of the first parameters, and somewhere close to that parameters should be stored, one after another.
Identifying patterns
Now, as we know what pattern we will look for, it is time to find them in code and guess functions of particular opcodes.
Read-only memory access
Let’s look at area near reference to our format string:
00091FB8 .word 0x1000000A # 04: ? 0x0A 00091FBC .word 0xD401D00C # 35: ? $0, $1, $26, 0x0c 00091FC0 .word 0x18600010 # 06: ? $3, $0+0x10 00091FC4 .word 0x1880000B # 06: ? $4, $0+0x0b 00091FC8 .word 0xD4012810 # 35: ? $0, $1, $5, 0x10 00091FCC .word 0xA8638608 # 2A: la $3, $3+0x8608 00091FD0 .word 0x400268A # 01: ? 0x268a 00091FD4 .word 0xA884AB5C # 2A: la $4, $4+0xab5c 00091FD8 .word 9 # 00: ? 0x09 00091FDC .word 0xBC160000 # 2F: ? $0, $22 00091FE0 .word 0x18600010 # 06: ? $3, $0+0x10 00091FE4 .word 0x1880000B # 06: ? $4, $0+0x0b 00091FE8 .word 0xA8638608 # 2A: la $3, $3+0x8608 00091FEC .word 0xA884AB73 # 2A: la $4, $4+0xab73 00091FF0 .word 0x4002682 # 01: ? 0x2682 00091FF4 .word 0x15000000 # 05: ?
After splitting instruction words into parts and decoding opcode, register and immediate values, we can see that string’s address is based on register $4 and stored also in register $4. If we look few lines upwards, we can see that register $4 is computed based on register $0 and offset 0x0b (marked in orange). Register $0 is often used to always store value 0. Now, if we look at original offset of string in firmware, we can see that it is 0xbab5c! So that instruction must store immediate value in register’s higher half. Therefore we just guessed function of opcode 06. Later this opcode will be described as lh (load high).
By the way we also discovered that almost surely firmware image is mapped to address 0 after loading to operational memory or more likely mapping EEPROM to address space.
Compare and jump
In the snippet above, another one thing is quite interesting. And weird at the same time. There are few instructions that seem to not contain any register encoded and have weird uneven offsets, often with quite low values. At this moment my theory is that shorter ones are some kind of jumps (like 0x91fd8) and longer ones are function calls (like 0x91fd0). Then it is time to try to find compare and jump pattern.
If we are right, then opcodes like 00, 04 are jumps and 01 means a call. After this section we should also tell conditional and unconditional jumps apart.
Ok, so we now need to go back to source code and find some good candidate for conditional jump. It should be as close to format string as possible. If we look at the snippet from Identifying target section, we can see one such check on line 4110. It checks for value being greater than zero. Going upwards a little bit, we encounter one 04 opcode, immediately preceded by 2F instruction:
00091FB0 .word 0xD4011808 # 35: ? $0, $1, $3, 0x08 00091FB4 .word 0xBC050000 # 2F: ? $0, $5 00091FB8 .word 0x1000000A # 04: ? 0x0A 00091FBC .word 0xD401D00C # 35: ? $0, $1, $26, 0x0c 00091FC0 .word 0x18600010 # 06: ? $3, $0+0x10 00091FC4 .word 0x1880000B # 06: ? $4, $0+0x0b
Now, if we look at occurrences of 2F opcode, we can spot that it is appearing usually near 04 opcode. However we cannot tell that they appear in exactly this order which is quite weird. On the other hand if we look at register this particular occurrence uses, it is quite likely it is compare opcode.
If we assume that 2F is cmp (compare) and 04 is jg (jump greater), we see that this more or less matches behavior we expect from the code immediately preceding sprintf from FreeRTOS source code.
However we still miss one information: what does the offset mean. If it is jump instruction, then we cannot jump 10 bytes ahead, because we would land in the middle of instruction. If we look again at source code, we can see that our jump should not go very far forward, so value should also not be too high. We can also exclude usage of register as address, because it would be register $10, which is not set anywhere near jump.
Having no other idea, I did an experiment. I multiplied jump value by 4, because length of instruction is always 4 and added next instruction address to result. Then I checked what is there and… bingo! It jumped above the sprintf call and ended up immediately after it. Some time later, I discovered that it is not completely truth. It happens that real formula is:
addr = imm * 4 + PC
Where imm is instruction argument and PC is program counter before executing the instruction (so address of jump opcode).
The question still is how more sophisticated compares are performed, because every one I’ve seen is just telling which value is greater. As there does not seem to be any flag in instruction, maybe there is no other option and to do that some arithmetic operation must be done to bring them to greater than operation?
Function call
Another thing, we can learn near the sprintf function is how parameters are passed to function. Signature for sprintf is:
int sprintf(char *str, const char *format, ...);
So after analyzing its call, we should know how at least two first parameters are passed. Let’s see how it looks like in machine code:
00091FC0 .word 0x18600010 # 06: lh $3, $0+0x10 00091FC4 .word 0x1880000B # 06: lh $4, $0+0x0b 00091FC8 .word 0xD4012810 # 35: ? $0, $1, $5, 0x10 00091FCC .word 0xA8638608 # 2A: la $3, $3+0x8608 # 0x108608 = pcWriteBuffer? 00091FD0 .word 0x400268A # 01: call +0x268a # 0x9b9fc = sprintf 00091FD4 .word 0xA884AB5C # 2A: la $4, $4+0xab5c # 0xbab5c = "%-16s %c %7u%s\t%2u%%\r\n"
Here, another interesting detail appears: last instruction setting the registers appears after the actual call. This is perfectly normal and can also be found on MIPS architecture. Its purpose is to allow concurrent execution of the two instructions.
Variadic functions
Now, if we scroll a bit upwards, we can see some interesting bunch of 35 opcodes. We know, that our call should have more than 2 parameters and thanks to format string we can tell that there should be exactly 5 extra parameters. Now if we count number of 35 opcodes, we see that these numbers match.
00091FA8 .word 0xD4012000 # 35: ? $0, $1, $4, 0x00 00091FAC .word 0xD401A004 # 35: ? $0, $1, $20, 0x04 00091FB0 .word 0xD4011808 # 35: ? $0, $1, $3, 0x08 00091FB4 .word 0xBC050000 # 2F: cmp $0, $5 00091FB8 .word 0x1000000A # 04: jg 0x91fe0 00091FBC .word 0xD401D00C # 35: ? $0, $1, $26, 0x0c 00091FC0 .word 0x18600010 # 06: lh $3, $0+0x10 00091FC4 .word 0x1880000B # 06: lh $4, $0+0x0b 00091FC8 .word 0xD4012810 # 35: ? $0, $1, $5, 0x10 00091FCC .word 0xA8638608 # 2A: la $3, $3+0x8608 00091FD0 .word 0x400268A # 01: call 0x9b9fc 00091FD0 # sprintf(pcWriteBuffer, "%-16s %c %7u%s\t%2u%%\r\n", 00091FD0 # $4, $20, $3, $26, $5) 00091FD4 .word 0xA884AB5C # 2A: la $4, $4+0xab5c
So, we can tell almost for sure that opcode 35 gets value of third register parameter and stores it at address computed as follows:
addr = reg1 + reg2 + imm
So e.g.
*($0 + $1 + 0x0c) = $26
Unfortunately with only that information, we can only guess the order of parameters, i.e. if $4 is first parameter or last one.
For future, we will denote opcode 35 as sw (store word).
Function prologue and epilogue
As we know exactly at which address the call will land, we can try to decode function prologue and epilogue, so what happens just after the call and just before returning back. Let’s see how such part of code looks, for example of sprintf function:
0009B9F0 .word 0x44004800 # 11: ret 0009B9F4 .word 0x8441FFF8 # 21: ? $2, $1, -0x08 0009B9F8 sprintf: .word 0xA9030000 # 2A: la $8, $3 0009B9FC .word 0x18600010 # 06: lh $3, $0+0x10 0009BA00 .word 0xD7E14FFC # 35: sw $31, $1, $9, -0x04 0009BA04 .word 0xD7E117F8 # 35: sw $31, $1, $2, -0x08 0009BA08 .word 0xD7E10FF4 # 35: sw $31, $1, $1, -0x0c
And to confirm it is the reverse at the end, let’s see epilogue:
0009BA60 .word 0x8521FFFC # 21: ? $9, $1, $31, -0x04 0009BA64 .word 0x8421FFF4 # 21: ? $1, $1, $31, -0x0c 0009BA68 .word 0x44004800 # 11: ret 0009BA6C .word 0x8441FFF8 # 21: ? $2, $1, -0x08
By the way immediately after sprintf there is strlen function, that is also called by function we are analyzing. So we see that registers stored with sw instructions are then recovered by opcode 21. Then we can safely assume it is reverse and denote it as lw (load word).
And we see that last jump in function is done by opcode 11, so we can denote it as ret (return). I still don’t know what is the meaning of its parameters. If we use standard decoding, it would be:
ret $0, $0, $9, 0x00
But I have no proof that it is the real meaning. I only see that sometimes this third hypothetical register have different value, but usually it is $9.
From my experience register saving, we see here is done to stack. If in this case it is also true, then we have two options for stack pointer: $1 and $31. Some more investigation must be done to tell which one is SP.
Other methods
We can also try to find constants other than strings. Then we have a chance, that there will be some arithmetic operation going on with them. Personally, I haven’t tried that approach, so I can’t show any example.
Another method might be finding references to some known structures. We can see one such structure in the function, we analyzed (TaskStatus_t). This is also left as an exercise to the reader.
Conclusion
Main focus of the analysis was on branching. As shown, we know quite a lot about not only branching, but also whole ABI. Now it should be possible, as soon as main entry of the system is found, to discover complete flow of the program.
We now know that first parameters are passed in registers $3, $4 and possibly so on. After analysis of function prologue and epilogue, we also know that here callee is responsible for preserving register values.
To sum up, we already know following instructions:
- 00: jmp off
- 01: call off
- 03: j? off
- 04: jg off
- 06: lh $r1, $r2, imm
- 11: ret
- 21: lw $r1, $r2, $r3, imm
- 2A: la $r1, $r2, imm
- 2F: cmp $r1, $r2
- 35: sw $r1, $r2, $r3, imm
We also know that in this architecture, there is mechanism of slots, identical with that in MIPS. Together with fixed-sized instructions and opcode and register field lengths, it is really similar to MIPS. Unfortunately it is not exactly the same, so reverse engineering of ISA have to be continued.
Unfortunately, after doing the research described here, I see that tools I used are not enough to do more reversing efficiently. So, before doing one step forward, I have to find a way to introduce more automation to the process. As soon as I succeed with this, I will write next part, so stay tuned!