Part 7: radare2 plugin for easier reverse engineering of OpenRISC 1000 (or1k)
For quite a long time I did not do anything about LKV373A. During that time the guy nicknamed jhol did fantastic job on my wiki, reversing almost complete instruction set for the encoder’s processor. Beside that nothing new was appearing. This has changed few days ago, when jhol published videos about the device. After that, someone found SDK that seems to match more or less the one used to produce LKV373A firmware. At the time of writing it was not available anymore. Although it provided a lot of useful information and what is important here, it gave a possibility to identify processor architecture. It turned out to be OpenRISC 1000 (or1k). Because it is known, I compiled binutils for that architecture. Unfortunately objdump, which is part of binutils is not the best tool for reverse engineering. Lack of hacks I made for my variant of binutils, which allowed me to follow data references, was making things even worse.
The conclusion was that I need some real reverse engineering tool for or1k architecture. Unfortunately, neither IDA Pro, nor Ghidra, nor radare2 does not have support for it, which is not so surprising, if I heard about it for the first time, when somebody identified LKV373A to have such core. Only few days later, I encountered good tutorial, explaining how to add support for new architecture. I didn’t need anything else.
I am not going to explain how to write disassembly plugin (called asm) for radare2. There are enough resources available. If one wants to try, my repository is quite nice place to start (notice template branch there).
Out of source build and installation
In radare2, it is possible to build plugins out of source. To do that in case of or1k plugins, repository has to be cloned first with usual git clone:
Last time, I showed how to do objdump, able to disassemble instructions for not yet supported processor – LKV373A encoder. This time, as promised in part 5, I am just publishing, what I was able to do.
Reverse engineering repo
Repository is located, as usually, on Github, here. The most important file there is printout of encoder firmware, generated with my fork of objdump. Also, there are few scripts, I used to make process more automatic. Especially useful for someone, who might want to reproduce the process or continue my work might be the ELF generator script. It is written in Python and uses my ELF-creation library from part 4. As there is no way to install the library where it should be – /usr/lib/pythonX.X/site-packages, I used MAKEELFPATH environment variable to find makeelf.
Less important scripts, but still sometimes useful, are the ones to generate graph of function cross-references. They are able of generating .dot file, which can be converted to PNG (which is bad way of making it useful – it is 32768 pixels wide) or opened somewhere. And I used Gephi to read the final graph.
binutils development
Also binutils fork was improved a little bit. It is now possible to see symbols on every jump and call instruction. Moreover I did a kind of hack to be able to see references to data, as they mostly consisted of two instructions – first setting upper half of register, then adding lower half. So in that case, objdump is now displaying content of register, which most of the time don’t work, as objdump parses code linearly, without caring about jumps. But, if this opcode pair is used to really reference some address, it is quite reliable, so it is possible to see the address, as well as symbol name, in same way as with calls. Also, there is much more information about opcode types, so completely unknown instructions had been eliminated. Some of them were not used a single time and were renamed to resXX – for reserved.
Does it make sense?
Now, as I know really a lot about the firmware, it is time to try to answer the question in the heading. Well, the goal of reversing the encoder was to find compression and checksum algorithm for SMEDIA/ITE firmware blob. And, as far as I know now, it is really likely that at least compression algorithm is in fact somewhere here. I can say that, because I’ve seen routine for processing the data that seem to be compressed in SMEDIA/SMAZ container. Moreover, SMEDIA itself is also processed here, in original form, as one of the firmware’s responsibilities is firmware upgrade, so it is being copied to some internal ROM. So, if both – compressed and decompressed versions of firmware is here, then decompression also should be somewhere.
Now, this reverse engineering work might take really, really long time to get some results, but on the other hand, I might find, what I am looking for today. So, now the topic will probably seem to be dead for some undefined time.
After part number four, we already have ELF file, storing all the data we found in firmware image, described in a way that should make our analysis easier. Moreover, we have ability to define new symbols inside our ELF file. The next step is to add support for our custom architecture into objdump and this is what I want to show in this tutorial.
Finding best architecture to copy
If we want to set up new architecture in objdump code, we need to learn interfaces that need to be implemented. It would be easier if we can use some existing code to do so. After some looking into the binutils’ code I learned that what is of special interest are bfd and opcodes libraries. They contain code dedicated to particular architectures. The first one seem to be related to object file handling (which in our case is ELF), so we should not tinker with it too much. Second one is related to disassembling binary programs, so is what we are looking for.
I did some quick examination of source code related to popular architectures and it seems not to be easy to adjust to our needs. Architecture I found to be best suitable for modification is Microblaze. Its source seem to be quite well-written, clean and short. Also from my research of architecture name for LKV373A (part 2, failed by the way) I also remember it is quite similar to the one present in LKV373A, so it is even better decision to use it.
Compiling objdump for target architecture
At first it is useful to learn how to compile objdump, so it will be able to disassemble program written for our target. Microblaze is not really a mainstream architecture, so there aren’t many programs compiled for it available online after typing 'microblaze program elf' into usual search engine. However, I was able to find 2 of them, so I was able to verify that compilation worked. If you can’t find any, I uploaded these to MEGA, so they can serve as test cases. First one is minimal valid file, the other one is quite huge.
Compilation is very easy. The only thing that needs to be done beside usual ./configure && make && make install is adding target option to configure script. So, the script looks as follows:
./configure --target=microblaze-elf
Of course, install step can safely be skipped as well as compilation of other tools, beside objdump. objdump itself seem to be built using make binutils/objdump. However it can’t be build successfully using that shortcut, so whole binutils package must be configured the way, everything not buildable is excluded from the build.
Setting up own architecture
Next step is to add support for our brand new, custom architecture to binutils’ configuration files and copy microblaze sources, so they will simulate our architecture, until we will write our own implementation. Then it should be possible to test objdump again, against our sample microblaze programs and disassembly should still work.
Even without any modification to binutils’ source or configs, it should be possible to configure it for any random architecture. The only constraint is format of the target string: ARCH-OS-FORMAT, where FORMAT is most likely to be elf. So, if we pass lkv373a-unknown-elf as target, it will work. -unknown part is usually skipped and this will not work. If we need it to work, config.sub must be modified. config.sub is used to convert any string, passed to configure into canonical form, so in our case lkv373a-unknown-elf. If it detects, that it is already in canonical form, it does nothing.
Final configure command will be slightly more complex, as we have to disable some parts, that are not of our interest and requires additional effort to work:
Although passing something random as target option works on configure stage, it will obviously fail on make stage. What make is doing at first is configuring all the sublibraries. What is of our interest is bfd and opcodes. And the first one fails. So this is the first problem, we need to get rid of.
bfd/config.bfd
The purpose of this file is to set some environment variables depending on target architecture. If it does not know the architecture, it returns error to caller, which is probably bfd’s configure script, called by make. According to documentation in file header, it sets following variables:
targ_defvec – default vector. This links target to list of objects that will provide support for ELF file built for specific architecture (stored in bfd/configure.ac)
targ_selvecs – list of other selected vectors. Useful e.g. when we need support for both 32- and 64-bit ELFs. Not needed here.
targ64_selvecs – 64-bit related stuff. Used when target can be both 32- and 64-bit, meaningless in our case.
targ_archs – name of the symbol storing bfd_arch_info_type structure. It provides description of architecture to support.
targ_cflags – looks like some hack to add extra CFLAGS to compiler. We don’t care.
targ_underscore – not sure what it is, should have no impact on our goals (possible values are yes or no)
To sum up, what we need to do on this step is to define default vector, we will later add to configure.ac and set name of architecture description structure. The structure itself will be defined later. Finally, I ended up with the following patch:
Unfortunately, as we did modifications to .ac script, we now need to rebuild our configure. From my experience, any tinkering with autohell, after solving one problem, creates 5 more. We need to get into bfd directory and reconfigure project:
cd bfd
autoreconf
Now, if it worked for you, you should definitely go, play some lottery 🙂 . For me it said that I need exactly same version of autoconf as used by binutils’ developers. Because autoconf is so great, probably what I will show now is completely useless for anyone, but hacks I needed to do are at first to add:
20 m4_define([_GCC_AUTOCONF_VERSION],[2.69])
to the beginning of configure.ac file. Then bfd/doc/Makefile.am contains removed cygnus option at the beginning, in AUTOMAKE_OPTIONS, so we need to remove it. After that doing automake --add-missing, as autoreconf suggests, and then again autoreconf should solve the problem. But, as I said, this will probably not work for you. I can only wish you good luck.
(if were following the steps, you might have noticed that autoconf complained about not being in version 2.64 and we overridden version from 2.69 to 2.69 and it worked 🙂 , don’t ask me, why, please!)
After this step, compilation should start (and obviously will fail miserably on bfd as it misses few symbols). Now its time to make bfd compilable.
bfd/elf32-lkv373a.c
This file is meant to provide support for custom features of ELF file. As we don’t have any, we can safely do nothing here. Good template of such file is elf32-m88k.c as it does exactly this.
One thing that seem to be important here is EM value of architecture described. EM is an enum used in ELF file to define target architecture, so it might be required to adjust in our new elf32-lkv373a.c file. By the way definition of this value have to be added to include/elf/common.h:
It might also be a good idea to add it to elfcpp/elfcpp.h. To make the file compile, it is necessary to add following to bfd/bfd-in2.h as value of bfd_architecture enum:
2398 bfd_arch_lkv373a, /* LKV373A */
bfd/archures.c
As we declared bfd_lkv373a_arch as symbol with CPU description structure, we now need to add this declaration to archures.c, as this is the file, where it will be used. We have to add:
Similar situation is in targets.c file. Here we have to provide declaration of our vector as bfd_target. This will be another structure, which seem to be generated automatically, so we should not care about it.
This last file, we need in bfd, provides bfd_arch_info_type structure and… that’s it! Can be easily borrowed from cpu-microblaze.c with only slight modifications. One thing that needs explanation here is section_align_power. As far as I understand it, it is power of two to which the beginning of the section in memory must be aligned. It should be safe to put 0 here, as we are not going to load our ELF into memory.
This should close the bfd part of initialization. As you can see, there was no development at all to be done here. Let’s now go to opcodes library.
opcodes/configure.ac
At first we need to define objects to build for LKV373A architecture in opcodes library. This is quite similar to what we had to do in configure.ac of bfd library.
Hopefully, -dis file will be enough to be implemented. I’ve made a copy from microblaze configuration. The same way we will copy whole source file and any related headers in the next step.
Now, similarly to bfd’s configure.ac, we have to reconfigure it. And again, nobody knows what errors we will encounter.
opcodes/disassemble.c
The only thing that have to be done here is to set pointer of disassemble function. For this following snippets should be added:
This is, where real stuff will happen. As our goal, for now, is not to make implementation of LKV373A architecture, but rather set everything up, so objdump will build, we can copy source file from microblaze-dis.c. It is also required to copy headers, related to MicroBlaze, used by this file, so:
opcodes/microblaze-dis.h
opcodes/microblaze-opc.h
opcodes/microblaze-opcm.h
And change include directives in them to link to lkv373a file, rather than microblaze ones.
Now, optionally we could change names of any symbols referring to name microblaze, but this should not be required, as original microblaze files should not be included in the build. The only change than need to be done is print_insn_microblaze into print_insn_lkv373a, as this is what we added to disassemble.c.
You should now be able to compile working objdump with LKV373A support (of course with wrong implementation, for now). We can now verify that everything works on slightly modified ELF file for MicroBlaze architecture (EM field must point to LKV373A – value must be 0x373a). Well done!
NOTE: all the steps, done till now are available on tutorial-setup tag in repository on Github.
Functions to implement
Now, finally the real fun starts. Bindings between opcodes library and objdump itself, require at least print_insn_lkv373a to be implemented.
What should happen inside this function is quite simple and can be described in following steps:
Gets bfd_vma and struct disassemble_info (called info below) as parameters
Read raw data containing instructions using info->read_memory_func
Call info->memory_error_func in case of any errors
Use info->fprintf_func to print disassembled instruction into info->stream
Optionally use info->symbol_at_address_func to determine if there is any symbol declared at address decoded from instructions
If symbol exists, call info->print_address_func
Return number of bytes consumed
Following is some documentation, I wrote for easier implementation (mostly translated inline comments), of functions to be called:
/** *\briefFunction used to get bytes to disassemble * * \parammemaddr Address of the current instruction * \parammyaddr Buffer, where the bytes will be stored * \paramlength Number of bytes to read * \paramdinfo Pointer to info structure * * \return errno value or 0 for success*/int (*read_memory_func)
(bfd_vma memaddr, bfd_byte *myaddr, unsignedint length,
struct disassemble_info *dinfo);
/** *\briefCall if unrecoverable error occurred * * \paramstatus errno from read_memory_func * \parammemaddr Address of current instruction * \paramdinfo Pointer to info structure*/void (*memory_error_func)
(int status, bfd_vma memaddr, struct disassemble_info *dinfo);
/** *\briefPointer to fprintf * * \paramstream Pass info->stream here * \paramchar Format string * \param ... vargs * * \return Number of characters printed*/typedefint (*fprintf_ftype) (void *, constchar*, ...) ATTRIBUTE_FPTR_PRINTF_2;
/** *\briefDetermines if there is a symbol at the given ADDR * * \paramaddr Address to check * \paramdinfo Pointer to info structure * * \return If there is returns 1, otherwise returns 0 * \retval1 If there is any symbol at ADDR * \retval0 If there is no symbol at ADDR*/int (* symbol_at_address_func)
(bfd_vma addr, struct disassemble_info *dinfo);
/** *\briefPrint symbol name at ADDR * * \paramaddr Address at which symbol exists * \paramdinfo Pointer to info structure*//* Function called to print ADDR. */void (*print_address_func)
(bfd_vma addr, struct disassemble_info *dinfo);
For easier start of development, this commit can be used as template. You can find effects of implementation according to this description on lkv373a branch of my binutils fork on Github. After this step, you should have working objdump, able to disassemble architecture of your choice.
Alternative way
According to binutils’ documentation, porting to new architectures should be done using different approach. Instead of copying sources from other architectures, developers should write CPU description files (cpu/ directory) and then use CGEN to generate all necessary files. However, I found these files way too complicated comparing to goal, I wanted to achieve, therefore I used the shortcut. In reality, however, this might be a better way, as the final result should be the support for new architecture not only in objdump, but also in e.g. GAS (GNU assembler). If you want to go that way, another useful resource might be description of CPU description language.
Plans for the future
As I am now able to speed up reverse engineering of both instruction set and LKV373A firmware, I am planning to create public repository of my progress and guess operations done by some more opcodes as I already know only few of them. So, I will probably push some more commits to binutils repo as well. I hope this will enable me to gain some more knowledge about LKV373A and allow, me or someone else, to reverse engineer second part of the firmware, which seem to be way more interesting that the one, I was reverse engineering till now.
As we should now be able to follow any jump present in the code, it is now time to make analysis more automatic. My target tool for that purpose will be objdump. However, we still have firmware image as raw dump of memory. To be able to use objdump easily, we need to pack our firmware into some container understandable by objdump. Most obvious choice is ELF (Executable and Linkable Format) and this is what I am going to use.
For the purpose of packing data into ELF, I’ve made Python library that makes it easier. For now, it is able to split firmware image into sections, like .text or .data, so objdump will be able to disassembly only the parts of firmware that are in fact a code. Moreover, it can define symbols inside the binary, so it is possible to store information, where certain functions starts and ends, same for any variables, like strings. As of now, there is no CLI interface for the program. If it turns out that such interface is necessary (like for addition of many symbols), it will be added.
Library code can be downloaded from Github. Currently, any LKV373A-specific modifications to this library is stored on branch lkv373a, to not rubbish main – master branch. Throughout this tutorial, I assume, we are using code on this branch, so there might be some LKV373A-specifics, especially regarding enum types (i.e. processor architecture enum).
At this point, I need to warn, that I am not going to describe internal structure of ELF file, nor any features that might be visible from outside, like sections concept, so if you are not familiar with them, it is good time to learn about them, as it might be very difficult to understand, what I am writing about. There are many good resources explaining them. Ones I was using are: this blog post and this documentation.
Creating new ELF
Example code that creates brand new ELF file is as easy as:
This, at first does all necessary imports, then creates new ELF object in line 6, and, finally, converts it to bytes object and immediately writes to file descriptor. That’s it!
After this, you should get valid, empty ELF file for architecture called lkv373a, which, obviously does not exists and no other program know how to handle, but we are going to change that in future.
While creating ELF object, few things can be defined, in addition to architecture id. They are all described in documentation, I will mention near the end of this tutorial. You are also free to dig in structure of ELF object. There is no encapsulation in it and structure validation is very permissive, so even completely broken ELFs could be produced, if needed.
Adding section
Next step is to add some sections to our ELF file.
At first, I am extracting them from firmware image and then inserting them to ELF object. append_section is a handy wrapper to low-level modifications that must be done on ELF structure, hidden under what we can see as ELF instance (these low-level structures are, however still available to the user as ELF.Elf member).
Modifying section attributes
Ok, so now we have sections in our ELF file, ready to save to disk. Before that, one thing can yet be done: setting proper attributes. They tell readers, if program is able to write or execute sections of memory, among other features, I am going to ignore here. This might be useful, as some readers might be confused about what is code (text) and what is data. In our case, we have two text sections (.irq and .text), so we are going to set them executable flag (SHF_EXECINSTR). Furthermore, we will set SHF_ALLOC flag for any section that is going to be loaded into memory (so all of them).
Segments are another concept, existing beside sections. They are stored in program header of ELF file and are somehow linked to section data. They allow to define another set of attributes to areas in memory. I don’t think they will be required to define, to perform analysis in objdump, but since at least one such program header, defining segment must exist in ELF file of type executable, there is interface similar to this for sections.
To define new segment, based on .text section, you can issue:
elf.append_segment(txt_id, flags='rx')
This also marks the segment as read and executable, but not writable.
Loading existing ELF
Loading existing ELF can be easily done from file with:
newelf, b = ELF.from_file('lkv373a.fw.elf')
Alternatively, it can also be loaded from bytes object:
fd = os.open('some.elf', os.O_RDONLY)
b = os.read(fd, 0xffff)
os.close(fd)
manualelf, b = Elf32.from_bytes(b)
In latter case, I assumed that os library is already imported into python.
Adding a symbol
This is very useful for making analysis of code. New symbol can be added using calls like:
First call defines function of length 0x44 in .irq section. To do this, ID of .irq section must be known. Luckily, we want to add symbol at the beginning of the section, so as offset, 0 was provided.
In the second case, we also want to define a function, but now we only know absolute address of the function (0x9b9f8), but what we need to pass is offset in .text section. To achieve this, we need to subtract address of the start of .text section (0x7d100).
In the last example, we define a string as an object of certain address and length. Both address and length are computed by subtracting absolute addresses. This symbol will be marked as local, which is default behavior for append_symbol function.
Library documentation
There are many more things possible to do using makeelf library. What I showed here is mostly, what is possible using high-level wrappers, doing many things under the hood. But as there is also low-level interface, virtually anything is possible.
To make exploring interfaces easier, I’ve made doxygen documentation for most of the library. It can be found on my server, here. Feel free to use the library for anything you want.
Conclusion
The library presented here should allow us make one step further to easy to use reverse engineering environment. It will by the way allow to store new findings in easily-modifiable Python scripts.
What I showed in examples to library interfaces split LKV373A firmware image into 4 sections. At this moment I already know that there are at least 6 sections, where code and data are in two parts (forming ICDCDS layout, where I-irq, C-code and so on). Also there should be some more symbols possible to place at this moment.
If I succeed in porting objdump, or any other tool able to disassemble ELF file, next step would be to publish Python script, utilizing library presented here, that annotates LKV373A firmware. So stay tuned, I hope there will be many further interesting findings throughout this reversing process!
As I wrote in previous part, my choice is in fact reverse engineering instruction set. The goal of this post is not to reverse-engineer whole instruction set, because even in RISC architectures some of the instructions might be quite rarely used.
Before starting the actual reverse engineering, place where such analysis would be easiest should be identified. Then it might be possible to use often repeating patterns to guess instructions that the pattern consists of. The result of this tutorial will be description of opcodes related to jumping and few other often used opcodes, mostly related to memory operations.
Identifying target
Data region
As written above, first step is to find good target. As was shown in previous article, it is possible to find references to constants mixed into code.
In the picture on the right one especially interesting information can be seen – it seems that as an operating system FreeRTOS was used. FreeRTOS is open source project, so its source code can be downloaded.
This information could be later possibly used to link compiled code with FreeRTOS source code. Let’s look into source code to find some useful location. As we already know the encoding of opcode for an operation on strings, finding some string in code might work. I was able to identify one such place in tasks.c file. It is shown on snippet below:
4110 if( ulStatsAsPercentage > 0UL )
4111 {
4112 #ifdef portLU_PRINTF_SPECIFIER_REQUIRED4113 {
4114 sprintf( pcWriteBuffer, "\t%lu\t\t%lu%%\r\n", pxTaskStatusArray[ x ].ulRunTimeCounter, ulStatsAsPercentage );
4115 }
4116 #else4117 {
4118 /* sizeof( int ) == sizeof( long ) so a smaller4119 printf() library can be used. */4120 sprintf( pcWriteBuffer, "\t%u\t\t%u%%\r\n", ( unsignedint ) pxTaskStatusArray[ x ].ulRunTimeCounter, ( unsignedint ) ulStatsAsPercentage );
4121 }
4122 #endif4123 }
4124 else4125 {
4126 /* If the percentage is zero here then the task has4127 consumed less than 1% of the total run time. */4128 #ifdef portLU_PRINTF_SPECIFIER_REQUIRED4129 {
4130 sprintf( pcWriteBuffer, "\t%lu\t\t<1%%\r\n", pxTaskStatusArray[ x ].ulRunTimeCounter );
4131 }
4132 #else4133 {
4134 /* sizeof( int ) == sizeof( long ) so a smaller4135 printf() library can be used. */4136 sprintf( pcWriteBuffer, "\t%u\t\t<1%%\r\n", ( unsignedint ) pxTaskStatusArray[ x ].ulRunTimeCounter );
4137 }
4138 #endif4139 }
4140 4141 pcWriteBuffer += strlen( pcWriteBuffer );
vTaskGetRunTimeStats formatting strings
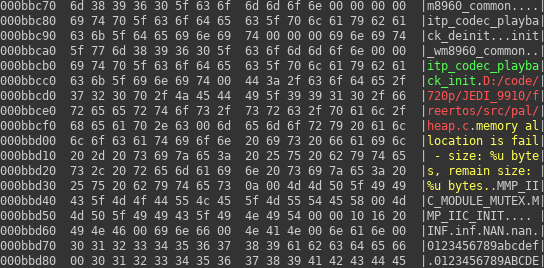
If we look at code before the snippet, we can see that the function is surrounded with ifdefs and is meant to be turned on only for demo purposes. Also searching for complete formatting string from sprintf function above fails on LKV373A firmware. Fortunately it is present in code and happens to have some modifications. One of them is the formatting string we were searching for. I was able to identify them starting at offset 0xbab2f. You can see it on hexdump. What is a bit surprising is that there are four such strings, while we expected only two in whole code. But "IDLE" string after them is confirming that it must be tasks.c module.
Now we can use method shown on previous tutorial about processor identification to find references to these strings. Finally I found usages of offsets 0xbab5c and 0xbab73 (marked in green and blue) near offset 0x91fd4.
At this moment, we have machine code and source code that is very likely to be compiled one to one into this machine code. We can also see here very useful side-effect of open source popularity: we have a system that has quite unusual function and is using open source software. So we can conclude that we can be almost sure that any random part of code also has open source software in itself.
Code patterns
As we already have quite reliable anchor for our analysis, we could try identifying more opcodes. But, to make things easier, I want to go the pattern matching way. Whichever architecture you analyze, you see some patterns that are same or almost the same on any architecture. This is especially true on RISC architectures, as they have very limited set of functions, so compiler have to join two or more instructions to get desired high level functionality. It this section, I will describe some of such patterns, I was able to identify and decode in LKV373A firmware. They are:
Function call
Function prologue and epilogue
Read-only memory access
Compare and jump
Variadic functions
Following is short description of the above patterns.
Function call
This is main element of ABI (Application Binary Interface) from the point of view of a programmer. Therefore it should also be well-known, even to people not involved in assembly programming or reverse-engineering. It is all about the method of passing arguments, before a call to a function.
Let’s see how such a call looks on MIPS architecture:
As we can see in case of MIPS, arguments are passed in registers named a0, a1, a2 and so on. Then address of function to call is loaded to t9 and jalr (jump and link register) is performed. Usually, in case of ABI, where arguments are passed in registers, when number of arguments is greater than number of such registers, they are passed through memory (i.e. stack).
Function prologue and epilogue
When performing a call to different function, state of the processor have to be preserved, so after the call it is again the same as before (with exception of few registers, used e.g. for return value passing). This operation may be done by caller or callee. Let’s look again at MIPS code to see how it works there:
I think there is nothing special to comment here. The opposite happens on function epilogue and additionally, immediately after that return instruction should appear.
Read-only memory access
This one is already partially analyzed on previous part of this series. It is usually appearing where some strings need to be used in code. Strings written in code as literals are stored in part of the memory where they shouldn’t be modified. Then theirs addresses are computed using some base register, or directly if code is not relocatable. This is how it works on MIPS:
lwt9,-30404(gp)
But, as we can see on previous post, we have something missing on our mysterious architecture. There, address was computed as $3=$3+0xbadadd. So, we should expect that register used should be set to something before that.
Compare and jump
This is after calling conventions, another extremely popular scheme. It usually consists of two opcodes. At first two numbers are compared, and some flags in processor are set. Then based on the state of one of the flags, jump is performed, or processing is continued if flag has value different than we expect. This time, let’s see how it works on x86 platform, as MIPS uses a bit different philosophy:
cmp [ebp+arg_4], eaxjnzloc_404CEB
On x86 cmp instruction causes the subtraction of two parameters, without actually storing the result, but only updating the FLAGS register, so it is known if the value is zero, or the overflow happened, and so on. Then based on flag value (in this case if zero flag is not set), jump occurs, or not.
Variadic function
Variadic function is function that can get variable number of parameters. The most popular example of such function is printf. It accepts format string and parameters, which number depend on format string. On system, where parameters are passed through registers, I expect it to get format through register and rest of parameters through stack or dedicated structure, so generally memory. Once we know how constants are accessed, it should be quite easy to identify, as it most likely will get format string as one of the first parameters, and somewhere close to that parameters should be stored, one after another.
Identifying patterns
Now, as we know what pattern we will look for, it is time to find them in code and guess functions of particular opcodes.
Read-only memory access
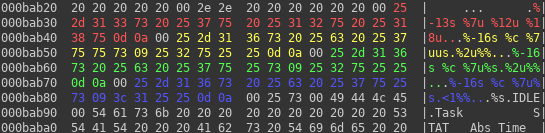
Let’s look at area near reference to our format string:
After splitting instruction words into parts and decoding opcode, register and immediate values, we can see that string’s address is based on register $4 and stored also in register $4. If we look few lines upwards, we can see that register $4 is computed based on register $0 and offset 0x0b (marked in orange). Register $0 is often used to always store value 0. Now, if we look at original offset of string in firmware, we can see that it is 0xbab5c! So that instruction must store immediate value in register’s higher half. Therefore we just guessed function of opcode 06. Later this opcode will be described as lh (load high).
By the way we also discovered that almost surely firmware image is mapped to address 0 after loading to operational memory or more likely mapping EEPROM to address space.
Compare and jump
In the snippet above, another one thing is quite interesting. And weird at the same time. There are few instructions that seem to not contain any register encoded and have weird uneven offsets, often with quite low values. At this moment my theory is that shorter ones are some kind of jumps (like 0x91fd8) and longer ones are function calls (like 0x91fd0). Then it is time to try to find compare and jump pattern.
If we are right, then opcodes like 00, 04 are jumps and 01 means a call. After this section we should also tell conditional and unconditional jumps apart.
Ok, so we now need to go back to source code and find some good candidate for conditional jump. It should be as close to format string as possible. If we look at the snippet from Identifying target section, we can see one such check on line 4110. It checks for value being greater than zero. Going upwards a little bit, we encounter one 04 opcode, immediately preceded by 2F instruction:
Now, if we look at occurrences of 2F opcode, we can spot that it is appearing usually near 04 opcode. However we cannot tell that they appear in exactly this order which is quite weird. On the other hand if we look at register this particular occurrence uses, it is quite likely it is compare opcode.
If we assume that 2F is cmp (compare) and 04 is jg (jump greater), we see that this more or less matches behavior we expect from the code immediately preceding sprintf from FreeRTOS source code.
However we still miss one information: what does the offset mean. If it is jump instruction, then we cannot jump 10 bytes ahead, because we would land in the middle of instruction. If we look again at source code, we can see that our jump should not go very far forward, so value should also not be too high. We can also exclude usage of register as address, because it would be register $10, which is not set anywhere near jump.
Having no other idea, I did an experiment. I multiplied jump value by 4, because length of instruction is always 4 and added next instruction address to result. Then I checked what is there and… bingo! It jumped above the sprintf call and ended up immediately after it. Some time later, I discovered that it is not completely truth. It happens that real formula is:
addr = imm * 4 + PC
Where imm is instruction argument and PC is program counter before executing the instruction (so address of jump opcode).
The question still is how more sophisticated compares are performed, because every one I’ve seen is just telling which value is greater. As there does not seem to be any flag in instruction, maybe there is no other option and to do that some arithmetic operation must be done to bring them to greater than operation?
Function call
Another thing, we can learn near the sprintf function is how parameters are passed to function. Signature for sprintf is:
int sprintf(char *str, constchar *format, ...);
So after analyzing its call, we should know how at least two first parameters are passed. Let’s see how it looks like in machine code:
Here, another interesting detail appears: last instruction setting the registers appears after the actual call. This is perfectly normal and can also be found on MIPS architecture. Its purpose is to allow concurrent execution of the two instructions.
Variadic functions
Now, if we scroll a bit upwards, we can see some interesting bunch of 35 opcodes. We know, that our call should have more than 2 parameters and thanks to format string we can tell that there should be exactly 5 extra parameters. Now if we count number of 35 opcodes, we see that these numbers match.
So, we can tell almost for sure that opcode 35 gets value of third register parameter and stores it at address computed as follows:
addr = reg1 + reg2 + imm
So e.g.
*($0 + $1 + 0x0c) = $26
Unfortunately with only that information, we can only guess the order of parameters, i.e. if $4 is first parameter or last one.
For future, we will denote opcode 35 as sw (store word).
Function prologue and epilogue
As we know exactly at which address the call will land, we can try to decode function prologue and epilogue, so what happens just after the call and just before returning back. Let’s see how such part of code looks, for example of sprintf function:
By the way immediately after sprintf there is strlen function, that is also called by function we are analyzing. So we see that registers stored with sw instructions are then recovered by opcode 21. Then we can safely assume it is reverse and denote it as lw (load word).
And we see that last jump in function is done by opcode 11, so we can denote it as ret (return). I still don’t know what is the meaning of its parameters. If we use standard decoding, it would be:
ret $0, $0, $9, 0x00
But I have no proof that it is the real meaning. I only see that sometimes this third hypothetical register have different value, but usually it is $9.
From my experience register saving, we see here is done to stack. If in this case it is also true, then we have two options for stack pointer: $1 and $31. Some more investigation must be done to tell which one is SP.
Other methods
We can also try to find constants other than strings. Then we have a chance, that there will be some arithmetic operation going on with them. Personally, I haven’t tried that approach, so I can’t show any example.
Another method might be finding references to some known structures. We can see one such structure in the function, we analyzed (TaskStatus_t). This is also left as an exercise to the reader.
Conclusion
Main focus of the analysis was on branching. As shown, we know quite a lot about not only branching, but also whole ABI. Now it should be possible, as soon as main entry of the system is found, to discover complete flow of the program.
We now know that first parameters are passed in registers $3, $4 and possibly so on. After analysis of function prologue and epilogue, we also know that here callee is responsible for preserving register values.
To sum up, we already know following instructions:
00: jmp off
01: call off
03: j? off
04: jg off
06: lh $r1, $r2, imm
11: ret
21: lw $r1, $r2, $r3, imm
2A: la $r1, $r2, imm
2F: cmp $r1, $r2
35: sw $r1, $r2, $r3, imm
We also know that in this architecture, there is mechanism of slots, identical with that in MIPS. Together with fixed-sized instructions and opcode and register field lengths, it is really similar to MIPS. Unfortunately it is not exactly the same, so reverse engineering of ISA have to be continued.
Unfortunately, after doing the research described here, I see that tools I used are not enough to do more reversing efficiently. So, before doing one step forward, I have to find a way to introduce more automation to the process. As soon as I succeed with this, I will write next part, so stay tuned!
In the first part, I identified two main problems for further development. First one is unidentified checksum, appended to the end of firmware image. Second one is unknown LZSS-like compression algorithm, used to compress machine code of application processor’s firmware.
Encoder firmware
The thing that till now was more or less unexplored is encoder firmware. LKV373A consists of two processors – application processor using the firmware analyzed in first part and encoder, which reversing I am going to push forward with this article.
Target frmware that I am working on is called LKV373A_TX_V3.0c_d_20161116_bin.bin and is obtainable from danman’s firmware collection.
At first, encoder firmware looks completely different than ITEPKG. The latter was completely structured. This one starts with some data fields, then there is big block of randomly looking data, interlaced with some strings. At the end is familiar SMEDIA02 structure. And this block of “random” data is our target.
First idea I had was running binwalk with -A switch to look for some known opcodes. With no luck. But if we look closer, it seems that this in fact is some kind of machine code.
Finding target
Data region
Ok, what we know now is that in firmware image there is a region with many strings written one after another, like on the first hexdump. In another place there is quite a lot data where some of the words are similar to the other. One such fragment can be seen on another hexdump.
Presumable code region
So, we can guess, there is code region around 0x81680 and code region near 0xbbc70. Now the question is: how to prove it.
Before proving our hypothesis, one thing is worth noting. If we are right and bytes here are really machine code, then we can be almost sure that instructions are always (or almost always) encoded into 32-bit numbers. That fact is very useful, when we will try to find candidate architectures to test against our characteristics.
How to prove it?
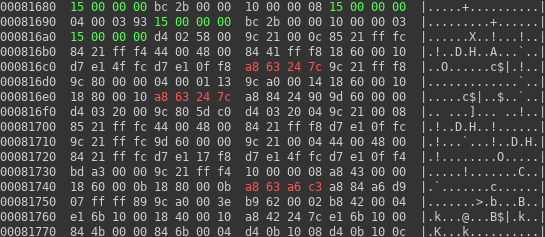
Fortunately, we can see one interesting candidate string. There is some debug message marked in red on data region. If our guess is valid, we should find some reference to it and moreover we can expect there would be only one reference to that particular string.
But now, there is another problem. How to find reference to string, saved somewhere in memory, at offset we have no chance to guess? Now the experience with any machine code might be useful. Usually assembly mnemonics are translated more or less in a form they are written by programmer. So, if we have hypothetical instruction:
add $1,$2+0x1234
Chances are it will be translated to something like:
0x21 0x01 0x02 0x12 0x34
Where lengths of any of these fields and maximum offset possible to write depends on particular architecture.
We can make another assumption. Usually if persistent memory (like EPROM) finally is mapped to operational memory, usually nobody designs device the way, where start of some section is not at address, padded to i.e. page size. So, if we are lucky final address of string in memory should have same least significant bits as our firmware image.
Then, connecting the dots, we can try searching firmware for let’s say two least significant bytes of string offset (0xbcc8). One more remark here: we still don’t know endianness of the processor. And what is worse, after reading firmware format description we don’t know it even more. So we have to check both variants.
Of course, it might happen that in case of different firmware for completely different architecture, all that might fail. There is only one advice to succeed with such analysis: be creative!
Hit found!
The first impression is that I was wrong. There are in fact 5 hits. But… If we look at general firmware structure, we can see that most of the hits are inside SMEDIA container, which as I described in previous post about reverse engineering LKV373A consists of mostly compressed data, and unlikely has any uncompressed code. So, success! We have only one hit inside area we suspected to be code.
By the way we know more than the area is in fact code section. We see that numbers in machine code are stored as big endian. And as we can, we can use 16 bits as offset here. That further narrows number of possible architectures. For instance, popular ARM architecture is little endian, so it is not likely to be used in this case.
I’ll leave as an exercise verification that we are right on another strings present in this firmware.
Further guesswork
Next thing that might ease things a bit is finding out what is a whole format of instruction, that is:
how many bits are used for opcode?
how many operands we can use?
how many bits encode an operand?
When I was doing the work I was not experienced enough to see it from plain word we already have. Then my approach was to guess meaning of 0xA8 opcode we see. As we know that it points to string in possibly write-protected memory, we should not expect it to perform any arithmetic or logic operations. It is rather likely to get pointer of string and store somewhere. Since architecture gives us only 32 bits to use per instruction it is not likely to copy memory somewhere. For me most probable operation is computation of string address, based on some base register and storage in another register. Therefore, I will call the operation: “Load Address” (abbreviated “la“).
Because that information alone does not give us any more hints, but can be used to match our mysterious architecture to one of the known ones, it is high time to do even more guesswork.
Specification matching
Wikipedia has quite useful page, that might help us. But, at first it is good to check some popular ones to see if they match.
As an example, I will use MIPS architecture. It is often used in embedded systems and was quite popular in routers, especially in past, when they were not running Linux. Furthermore it is the most popular architecture that might be big endian, so seems like perfect first check.
Now, we can find some hints on Wikibooks. On MIPS there is instruction format that might match our characteristics.
I Format
opcode
rs
rt
imm
6 bits
5 bits
5 bits
16 bits
After search in MIPS manual (its name is “MIPS32™ Architecture For Programmers Volume II: The MIPS32™ Instruction Set” and is probably no more available on original source, but rather some random sites, so no link here), we can see that instruction that has first 6 bits of a word matching our target (0b101010) is “Store Word Left” (swl), so it is not really what we expected.
Now, we have to move on and check another architecture, and another, and another, until we decide we can’t find anything matching. Or finally we will find something. In my case the result is fail. I checked:
MIPS
ARM
ARC
RISC-V
PowerPC
SPARC
MicroBlaze
Xtensa
IBM S/390
Motorola 68k
DLX
Mico32
LEON
OpenRISC
NIOS II
m32r
And nothing matched. So architecture here is something really uncommon. Because the device is probably performing HDMI signal processing beside being normal processor, it is likely it is in fact soft processor, programmed into some FPGA. Therefore it is likely, finding the architecture documentation will be impossible.
Decoding instruction format
Then we can try another approach. Let’s play a little bit and try to decode rest of instruction using above MIPS I format. First 6 bits means instruction opcode (0x2A or 0b101010), next are two 5-bit fields meaning destination and source register, so we have register 3 for destination and register 3 for source. That definitely makes sense!
So, our hypothesis is that we have 6-bit opcode, 5-bit operands and 16-bit offset encoding. Here, again proving that fact is left as an exercise for the reader.
Going back to our target instruction, we now know that it is executing code like that:
$3 = $3 + 0xbcc8
We will denote this instruction as:
la $3,$3+0xbcc8
What we know?
Now, to sum things up, we learned following things about device’s architecture:
32-bit (4-byte) static instruction length
big endian
6-bit opcodes (maximum number of opcodes is 0x40)
5-bit operands (32 general purpose registers available)
indirect addressing of up to 65535 bytes (0xffff)
What next?
As we know quite a lot information about the architecture, we can choose one of the two ways: try to find out what is the name of the architecture and find its documentation (not likely to succeed) or reverse engineer as much instruction as we can. My choice probably will be the latter and if I will succeed in pushing knowledge forward, I will try to describe the process in next article in series.
Recently, I bought LKV373A which is advertised as HDMI extender through Cat5e/Cat6 cable. In fact it is quite cheap HDMI to UDP converter. Unfortunately its inner workings are still more or less unknown. Moreover by default it is transmitting 720p video and does not do HDCP unpacking, which is a pity, because it is not possible to capture signal from devices like cable/satellite TV STB devices. That is why I started some preparations to reverse engineer the thing.
Fortunately a few people were interested by the topic before (especially danman, who discovered second purpose for the device). To make things easier, I am gathering everything what is already known about the device. For that purpose I created project on Github, which is to be served as device’s wiki. Meanwhile I was also able to learn, how more or less firmware container is constructed. This should allow everyone to create custom firmware images as soon as one or two unknowns will be solved.
First one is method for creation of suspected checksum at the very end of firmware image. This would allow to make modifications to filesystem. Other thing is compression algorithm used to compress the program. For now, it should be possible to dissect the firmware into few separate fragments. Below I will describe what I already know about the firmware format.
ITEPKG
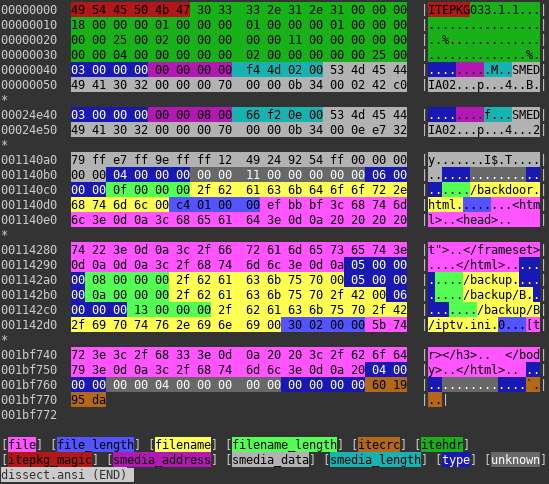
ITEPKG format (container content discarded)
Whole image starts with magic bytes ITEPKG, so this is how I call outer container of the image. It allows to store data of few different formats. Most important is denoted by 0x03 type. It stores another data container, that is almost certainly storing machine code for bootloader, and another entity of same type that stores main OS code. This type is also probably storing memory address at which content will be stored after uploading to device. Second important entity is denoted by type 0x06 and means regular file. It is then stored internally on FAT12 partition on SPI flash. There is also directory entry (0x05), that together with files creates complete partition.
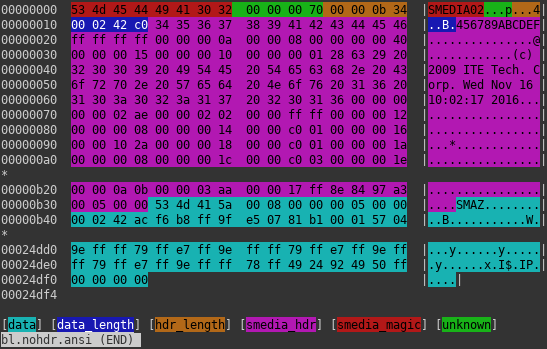
SMEDIA
SMEDIA container (header truncated)
Another data container mentioned on previous section is identifiable by magic SMEDIA. It consists of two main parts. Their lengths are stored at the very beginning of the header. First one is some kind of header and contains unknown data. Good news is that it is uncompressed. Second one is another container. Now the bad news is that it contains compressed data chunks.
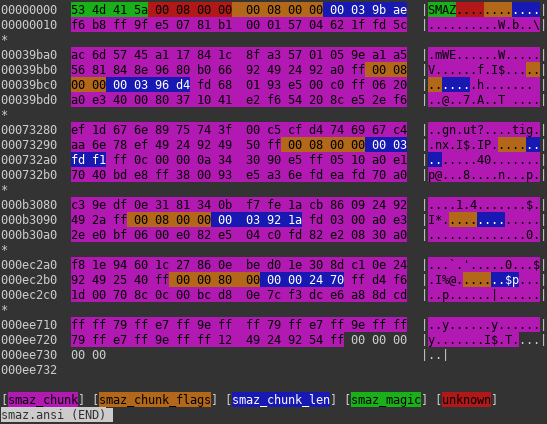
SMAZ
SMAZ container
This container’s function is to split data into chunks. One chunk has probably maximum length of 0x40000 bytes (uncompressed). Unfortunately after splitting, they are compressed using unknown algorithm, behaving similarly to LZSS and I have some previous experience with variant of LZSS, so if I say so it is very likely that it is true 🙂 . As for now, I reached the wall, but I hope, I’m gonna break it some time soon. Stay tuned!