rtorrent is very nice tool to download torrents quickly and on headless systems. However, while making such a quick use, I was caught by its weird design decision that it comes unconfigured and while not configured explicitly it does not store its session in any way, even as torrent files of jobs that were started. I can imagine that in many cases it is not a problem as still usually torrent files are easily available and if not using magnet to obtain one is not a problem. Unfortunately I ran into such a weird situation where I was not able to start a job again with just a magnet link and obviously was not able to download whole torrent at one run. Also saving session in rtorrent was not working. So the only chance for me to recover download job was to use meta file that rtorrent leaves behind for reason unknown. There is even Github issue discussing those files and requesting ability to use them to recover the job. But unfortunately it is still open. So the only way for me was to do it myself.
meta2torrent.py
Let me first show you this little, handy tool to do it automatically. To be able to use it you have to simply clone the repo and install all dependencies:
git clone https://github.com/v3l0c1r4pt0r/meta2torrent cd meta2torrent pip install -r requirements.txt
Then to convert meta file, you have to provide its location, name of the output torrent file and optionally list of trackers:
./meta2torrent.py --announce 'udp%3A//tracker.opentrackr.org%3A1337/announce' A8F2B5E67788128CD4F23DCFCB5826F2A5021A07.meta A8F2B5E67788128CD4F23DCFCB5826F2A5021A07.torrent
Unfortunately meta files do not seem to contain any trackers, so they have to be provided externally. It is also possible to skip, but in this case it might be harder to find peers for the download as you would need to base only on DHT for finding them.
How does it work?
While for ordinary user above knowledge should be sufficient, there might be some people wondering how it works, or (more likely) why it does not and how to fix that. The script is just a quick hack, written in one evening, so there are a lot of things that could go wrong.
So, basically meta file is almost identical as ordinary torrent file, while still being completely incompatible with it. It uses the same bencode encoding to pack structured data into a tree. But for some reason authors of this format did not keep identical structure, but rather cut one subtree of torrent root tree and dropped all the metadata beside it. This can be easily seen in the picture below.
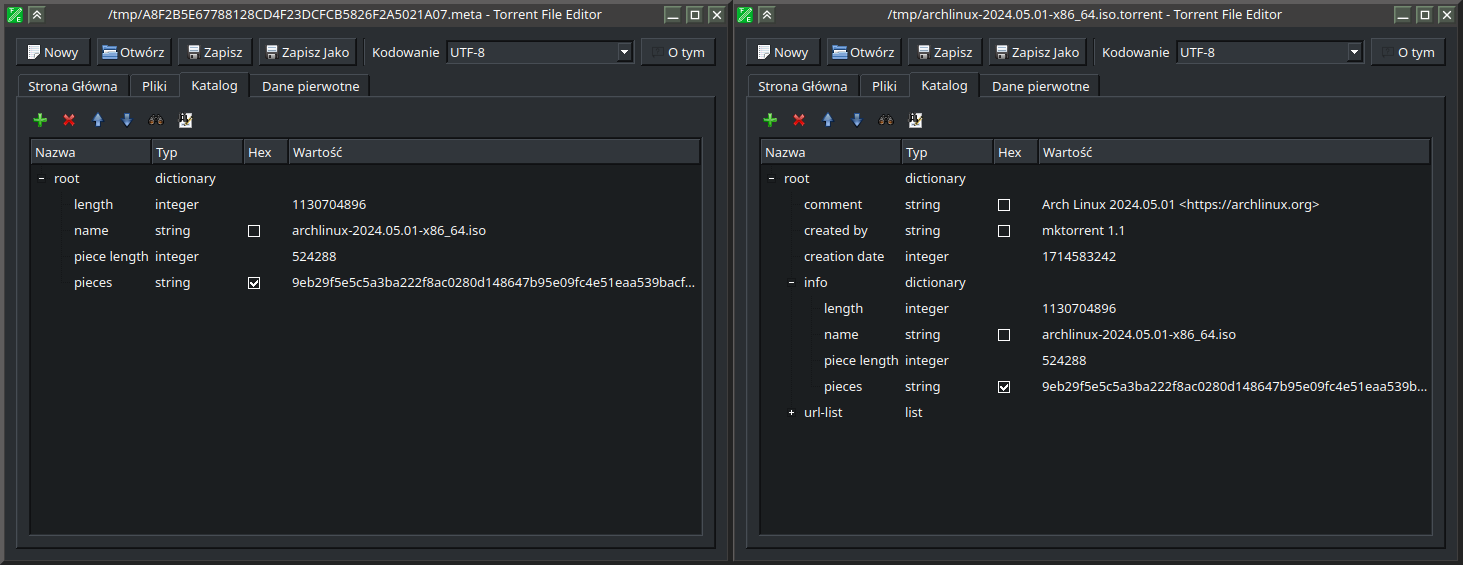
As can be seen, there are 4 nodes in meta file’s root node (length, name, piece length and pieces), while torrent file has info node directly in root, while same nodes are under it. Beside that in root there are some metadata nodes, that can be either easily generated, or copied from info. In this example there is no announce in torrent file, while usually it is there. Also there is url-list for HTTP download acceleration, this can be ignored here, it is optional and usually does not appear at all. There is also different variant of torrent files, where there is more than one file inside and in this case there is files node instead of length field, that describe each file in torrent. In such case, this files node also appears in meta file, as the rest shown here, so conversion algorithm does not change.
And this was as easy as that. Nothing more. Maybe there are more variations of torrent files that will generate errors with this script. Who knows. For me this was just a quick hack to solve a problem that occurred for the first time for me and it is likely that I will not encounter it anymore. The other lesson for me is to configure rtorrent before first use. If I did that, I would never encounter this issue. If you did this same mistake, hope I provided enough information to help you.